0. 요약
예전에 썼던 한국어 어휘강세 글의 후일담입니다. 이번에는 1935년 조선어독본에 녹음된 한국어 어휘들에서 나타난 강세들을 자료로 1930년대 한국어 어휘강세 양상을 생각해봅니다.
https://linguisting.tistory.com/199
한국어에 어휘강세가 존재한다면
목차 0. 도입어휘강세는 단어형 수준에서 결정되는 강세를 말한다. 영어는 어휘강세가 뚜렷하게 나타나는데, 규칙적으로 예측되는 경우도 있고, 기저형에서 결정되는 것으로 처리하는 어휘강
linguisting.tistory.com
목차

1. 조선어독본과 녹음본
조선총독부는 1911년부터 '보통학교 조선어독본'을 편찬 및 보급했다. 오늘날의 초등학교 '읽기' 교과서에 해당하는데, 소위 '민족말살통치기'라는 1930년대까지 꾸준히 개정판이 나왔다. 교과서를 제작하다보니 한글을 이용한 한국어 표기법을 정리하는 계기가 되었고, 아무래도 읽기용 책이다 보니, 1930년대에는 독본의 일부 챕터에 대해 '제대로 된' 표준발음을 녹음자료로 제작했다.
나는 역사학 전공자가 아니고, 민족사관이니 실증사관이니 하는 역사관을 전혀 모르기 때문에, 이것이 역사학적으로는 어떻게 이해되는지는 모르지만, 적어도 한국어 음운론적으로는 귀중한 자료임에는 틀림없다. 말소리 음파 그자체를 기록하는 기술이 보급된 시기 한반도는 안타깝게도 일제강점기였다. 그 당시 최신기술을 이용해 제도적으로 표준 조선어 음성 녹음을 제작했고 그것이 남아있다는 건 다행이다.
이 녹음에는 서울지역 보통학교 재학생들이 참여했다고 알려져 있는데, 이때 보통학교 5학년 재학생으로서 참여한 정계환 님께서 녹음 레코드판을 소장하고 계시다가 1990년대에 기증하셔서 녹음이 음원으로 추출되었다.
고양문화재단에서 덕양어울림누리 개관 당시 이를 기념하는 사업의 일환으로 독본 녹음본을 디지털화하여 인터넷으로 공개했었다. 나는 이 음원을 받아놓고 어디다 저장해놓고 있었는데, 이번에 컴퓨터 정리하다가 그걸 발견했다. 고양문화재단 홈페이지( https://www.artgy.or.kr/help/ulim/story_theater_05.asp ) 에서 배포되었었는데 지금은 링크가 깨져있다.😢 (아카이브된 웹페이지는 남아있다)
2. 강세부여이론과 30년대 단어들
최근 한국어 어휘강세 관련 블로그에 글을 썼었는데 요약한다면 이렇다: 1. 한국어 어휘강세를 분석한 두 선행연구(Kim 1998, 유채원 1989)가 가짜단어에 대해 다른 예측을 한다. 2. 두 연구의 예측 중 어떤 것도 나의 직관과는 맞지 않았다.
구체적으로 두 이론의 한국어 어휘강세 예측을 아주 거칠게 요약하면 아래와 같다.
- Kim19981: 1음절이 중음절이면 강세부여. 아니면 2음절에 강세부여
- 유채원19892: 가장 먼저 나오는 중음절에 강세부여. 중음절이 하나도 없으면 맨 오른쪽 경음절에 강세부여
그렇다면 만약 1930년대 한국어 어휘강세가 있었다면, 두 이론이 그 패턴을 예측할 수 있을까?
조선어독본 녹음 음원 초반에는 단순한 단어들 (모두 단일어는 아니다)을 읽는다. 이걸 바탕으로 1930년대에는 어휘강세가 있었는지 알 수 있을 것 같다.
https://www.youtube.com/watch?v=ByryqB3IDEM
단어나온 음성파일:
거기에 더한 Praat Textgrid:
나온 단어들은 아래와 같다. 아무래도 가장 처음 단원이다 보니까 모든 단어들이 다 받침없는 단순한 음절로 되어있다.
| 단어 | CV구조 | 음절개수 | |
| 1 | 소나무 | CV.CV.CV | 3 |
| 2 | 버드나무 | CV.CV.CV.CV | 4 |
| 3 | 두루미 | CV.CV.CV | 3 |
| 4 | 소나무가지 | CV.CV.CV.CV.CV | 5 |
| 5 | 아버지 | V.CV.CV | 3 |
| 6 | 우리아버지 | V.CV.V.CV.CV | 5 |
| 7 | 어머니 | V.CV.CV | 3 |
| 8 | 우리어머니 | V.CV.V.CV.CV | 5 |
| 9 | 가지 | CV.CV | 2 |
| 10 | 미나리 | CV.CV.CV | 3 |
| 11 | 바지 | CV.CV | 2 |
| 12 | 저고리 | CV.CV.CV | 3 |
| 13 | 두루마기 | CV.CV.CV.CV | 4 |
3. 가지 바지 (CV.CV)
가지와 바지의 강세부여 패턴은 2음절 강세부여인 것으로 보인다.
아래 스크린샷은 '가지'를 발음한 것인데, 2음절에서 조금 더 높은 pitch를 찍고 떨어진다. 만약 1930년대 한국어가 대구방언처럼 음의 높낮이로 강세를 표현했다면, 높은 음으로 발음된 2음절에 강세가 부여되었다고 볼 수 있을 것이다. 끝에 pitch가 떨어지는 건 단어말 패턴이겠지.

이 패턴은 '바지'에서도 비슷한 것같다.

일단 여기까지 봐서는 Kim1998과 유채원1989 모두 타당한 예측을 한다.
4. 두 이론의 예측이 갈리는 경우: 3음절어
이전 글에서도 언급했지만 Kim1998과 유채원1989가 갈리는 경우가 있다.
두 이론이 예측하는 한국어 비단어 강세 패턴은 아래와 같은데, CV.CV.CV일 때, Kim에 따르면 강세가 2음절에 떨어질 것으로 예측되나, 유채원에 따르면 3음절에 떨어질 것으로 예측된다. 물론 내 직관과는 거리가 있다. 내 발음에서는 1음절과 2음절에 강세가 들어가고 3음절이 좀 모호하게 발음된다.
| Kim (1998) | 유재원(1989) |
| 낙징보 | 낙징보 |
| 부돕바 | 부돕바 |
| 지소보 | 지소보 |
그렇다면 두 이론 중 1930년대 CV.CV.CV 단어의 강세패턴을 예측하는 것이 있을까?
녹음 중, 3음절 CV.CV.CV는 '소나무', '두루미', '미나리', '저고리' 이렇게 4개 있었다.
아래는 각각 소나무, 미나리, 저고리의 강세패턴이다. (두루미의 경우 녹음 품질이 좋지 못해서 제외했다.)
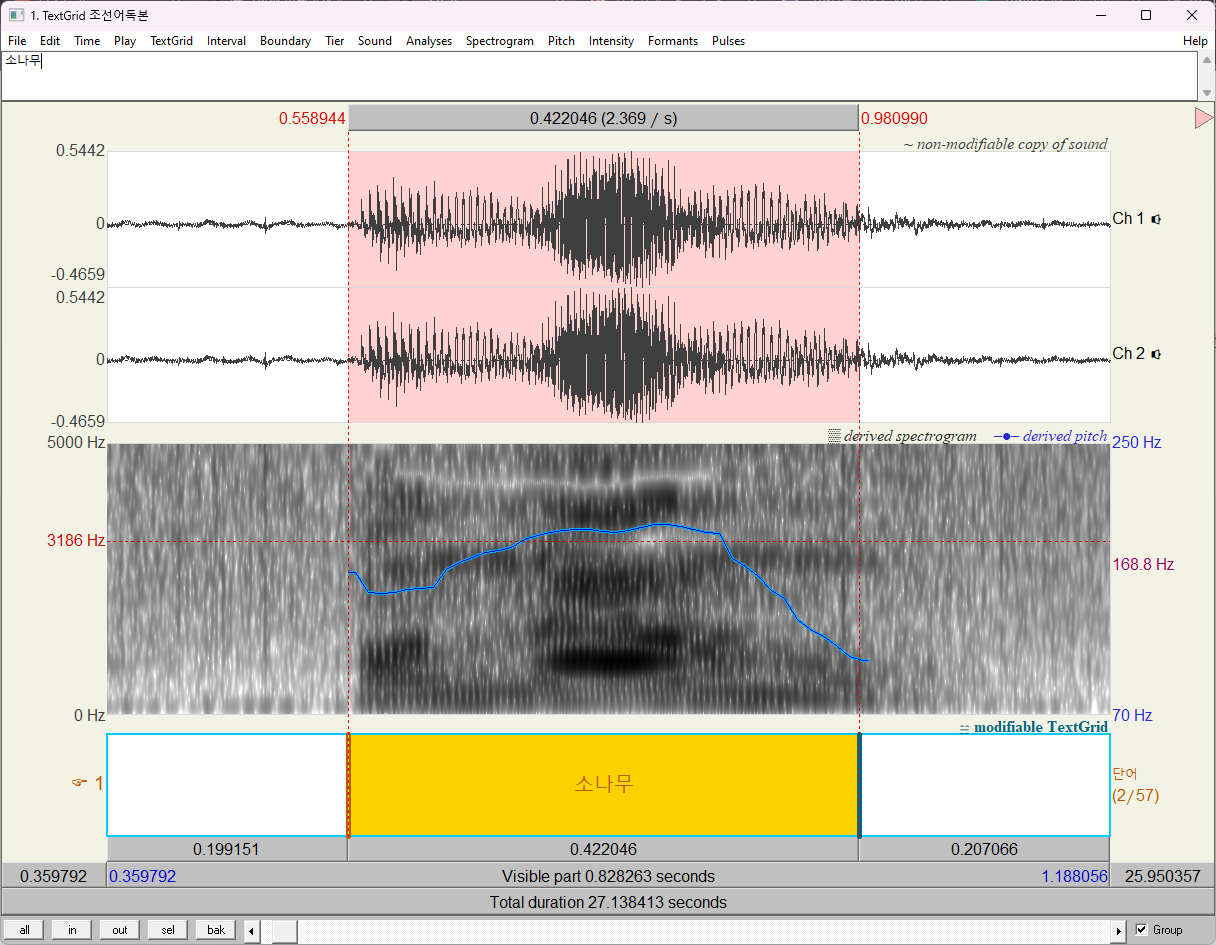
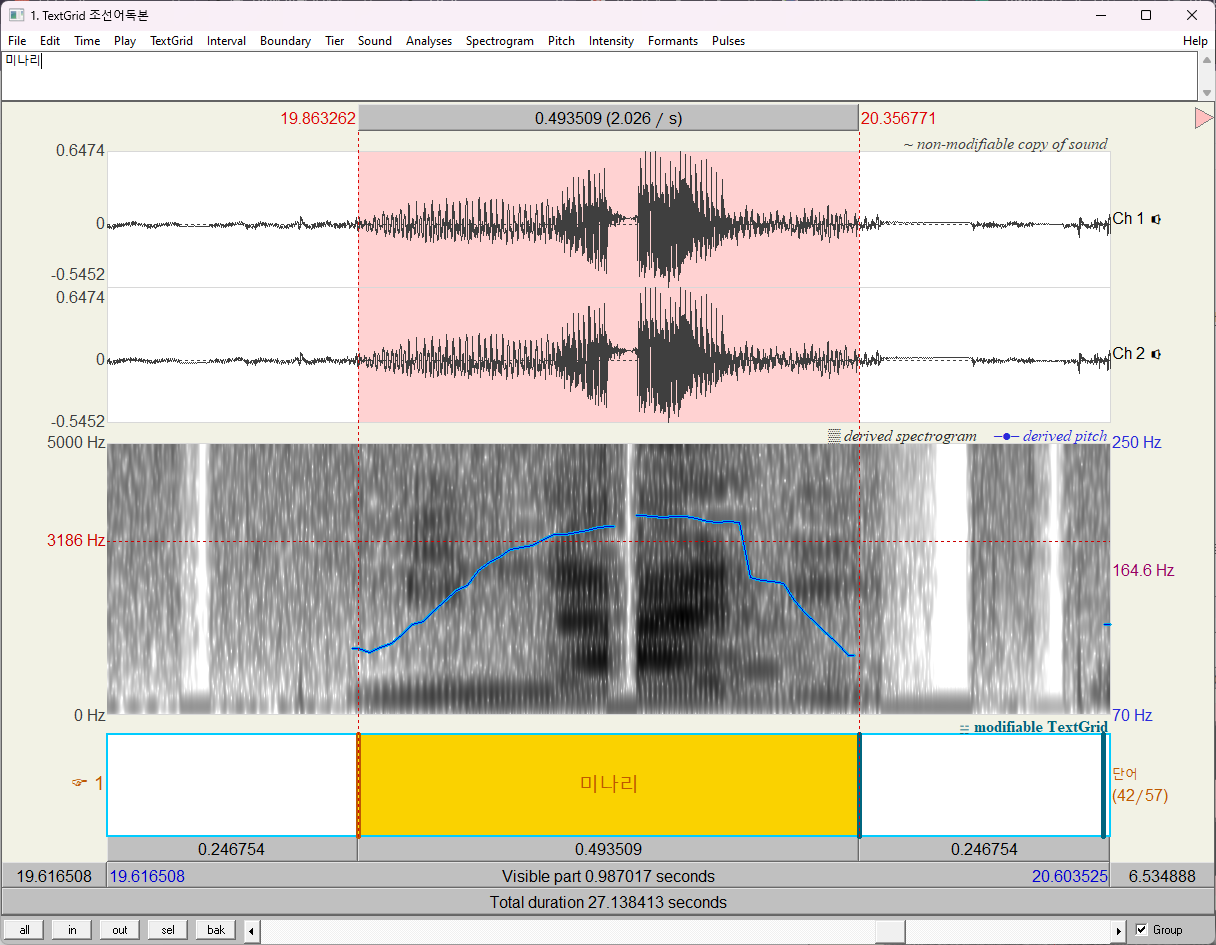

흥미롭게도 모두 단어의 중간부분의 pitch가 높았다. 만약 pitch를 올리는 것이 1930년대 한국어에서 어휘강세를 주는 방식이었다면 Kim (1998)의 예측이 옳다.
4. 아버지와 우리아버지
3음절어의 경우 중간부분 즉 2음절 부분에 강세를 주는 것으로 보인다. 그리고 Kim (1998)은 이것을 적절하게 예측한다. 그런데 모든 단어가 맥락 없이 독립적으로 나와있기 때문에, 정말 이게 어휘강세효과인지 아니면 절 혹은 그 이상 단위에서 나타나는 운율패턴인지 불명확하다.
3음절어에서 발견한 패턴이 정말 어휘강세인지 보기 위해서 이번에는 '아버지'와 '우리아버지'를 비교해보자. 만약 2음절 pitch 올리는 게 정말 어휘강세가 발현된 모습이라면, 두 경우 모두 아버지, 우리아버지 로 발음될 것이다.
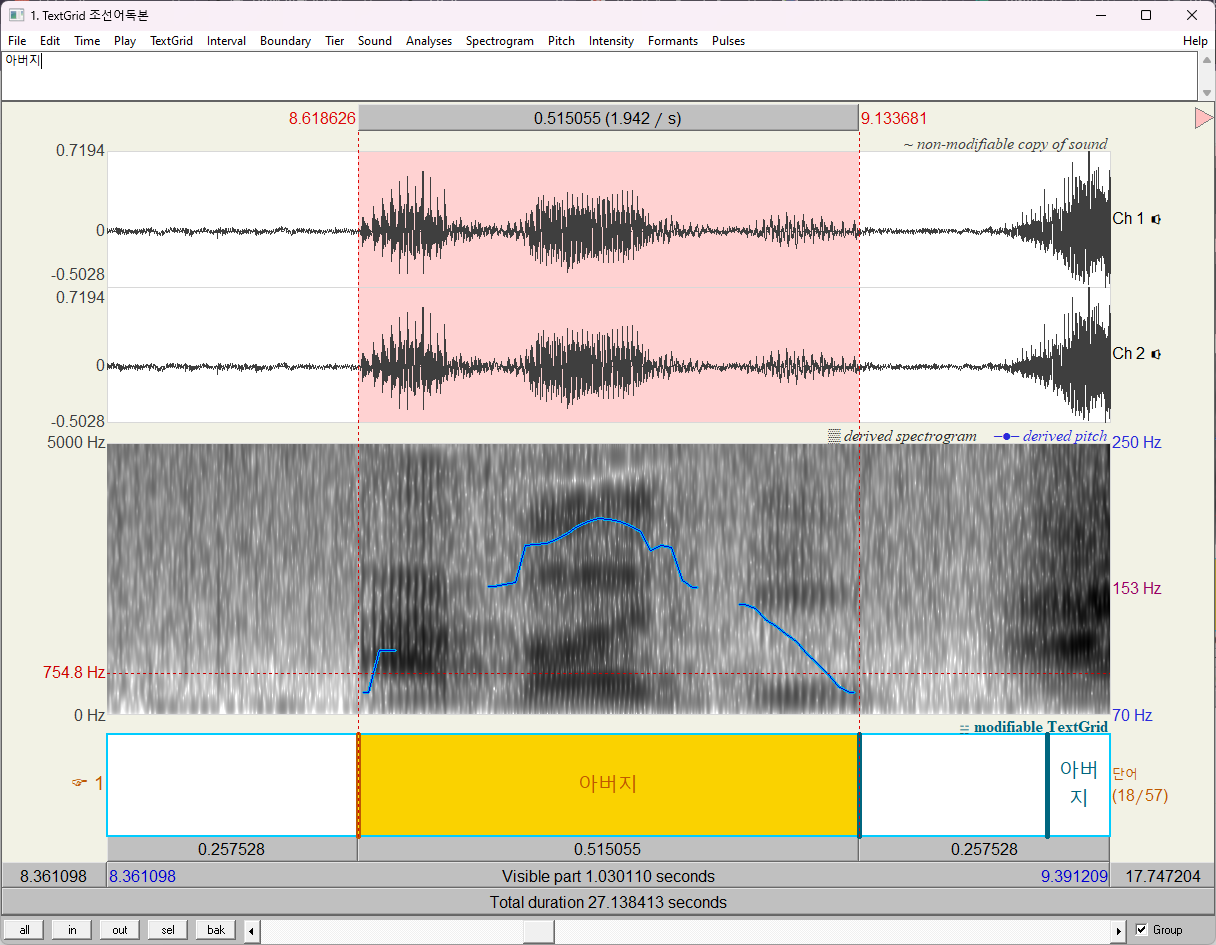
우선, "아버지"의 경우, 패턴이 2음절 pitch가 높은 것을 볼 수 있다.
그러나 "우리아버지"를 보면 좀 모호하다.
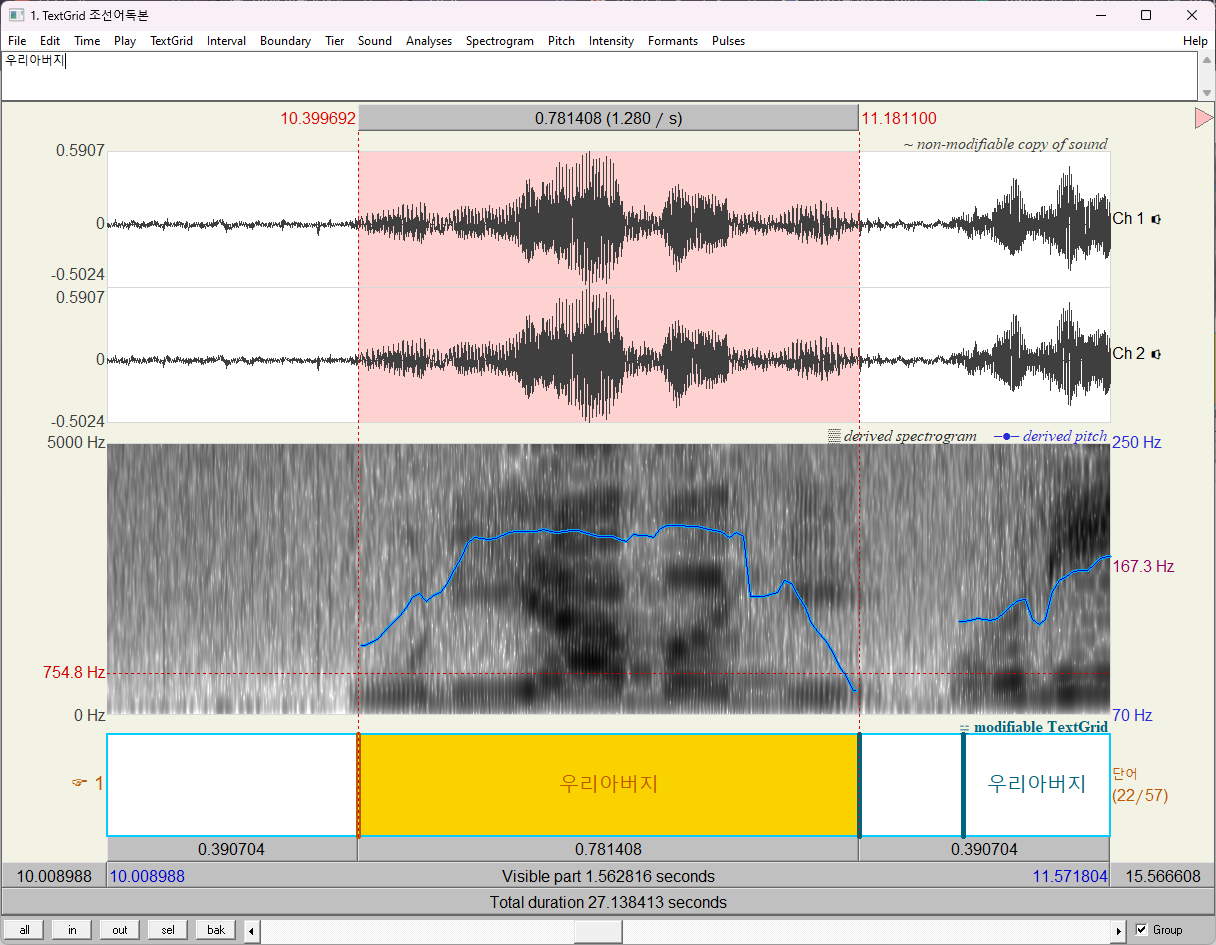
어짜피 그냥 보고 싶어서 보는 거니까 각 모음의 스펙트럼으로 추정되는 부분에 줄을 내 맘대로 그어보았다. (아래 스크린샷) 중간에 '리'와 '아' 사이의 중간음 [j]는 제외.
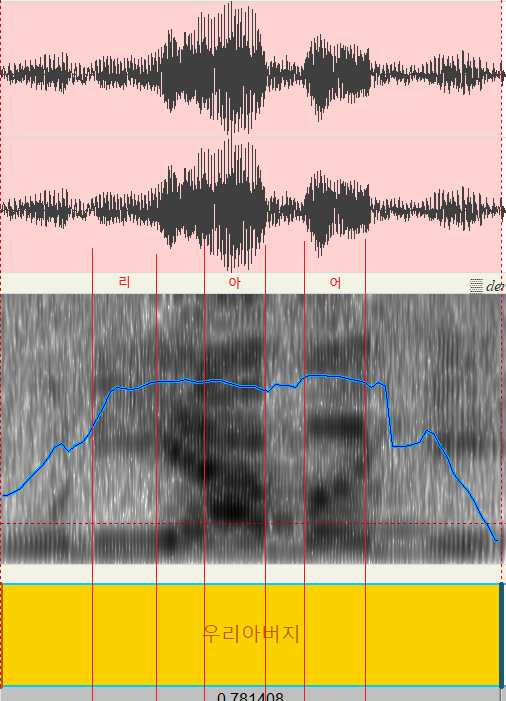
'버'의 '어' 모음의 pitch가 살짝 높은 것 같기도 하고.....
이럴땐 다른 단어쌍을 보는 게 낫다. 독본에는 '어머니'-'우리어머니' 쌍도 있다.
아래는 '우리어머니'다. 여전히 모호하다.

과장하자면
우리어머니
처럼 represent하고 싶은데, 실제로 Hz값 자체는 그리 크게 차이가 나지 않는다.🤣
5. 결론
저 녹음에 담겨있는 목소리의 주인들은 이미 이 세상에 없을 것이다. 그렇지만 살아계시더라도 데이터를 구할 수는 없을 것이다. "1930년대에는 어디에 어휘강세를 넣으셨습니까? 지금은 어디에 어휘강세를 넣으십니까?" 이렇게 질문을 할 수가 없기 때문이다. 그러나 우리어머니 열 번 발음시켜서 녹음할 수는 있을지도...
그래서 결국 결론은 없다. 어짜피 그냥 컴퓨터에서 '보물'을 발견한 기념으로 쓴 글이었음 🤗. 굳이 결론을 낸다면 '알수 없음' 혹은 '데이터가 더 필요함' 정도가 될 것이다.
난 그냥 재미로 겉핥기 했지만, 아마 누군가 이 데이터를 좀더 본격적으로 보아줄 사람이 있을 것이다. 아니, 이미 그런 연구가 이루어졌을지도 모를 일이다.
- 글이 유익했다면 후원해주세요 (최소100원). 투네이션 || BuyMeACoffee (해외카드필요)
- 아래 댓글창이 열려있습니다. 로그인 없이도 댓글 다실 수 있습니다.
- 글과 관련된 것, 혹은 글을 읽고 궁금한 것이라면 무엇이든 댓글을 달아주세요.
- 반박이나 오류 수정을 특히 환영합니다.
- 로그인 없이 비밀글을 다시면, 거기에 답변이 달려도 보실 수 없습니다. 답변을 받기 원하시는 이메일 주소 등을 비밀글로 남겨주시면 이메일로 답변드리겠습니다.
'생각나는대로' 카테고리의 다른 글
| [실험은 어려워] 2. 주제와 방법론을 고정하기 (2) | 2024.11.09 |
|---|---|
| [실험은 어려워] 1. 실험할 결심 (5) | 2024.11.08 |
| 한글날 기념 (2) | 2024.10.09 |
| 한국어에서의 영어 차용과 모음삽입 (6) | 2024.10.06 |
| "었어서"의 분포 (-었 사용 추가사례 포함) (3) | 2024.09.09 |