0. 요약
이 글은 박사 후보생의 연구 발표에 갔다가 거기에서 질문하지 못한 너무 철학적인(?) 질문들을 메모하는 것이 목적입니다. 덧붙여서 이론언어학의 연구 관심 분야 가운데 하나인 learnability에 대해서도 조금 소개합니다.
오늘날 형식주의 이론 언어학에서는 기계적 방법론에 많이 의존할 수밖에 없는데, 이러한 시대에 연구를 한다는 것이 과연 무엇인가에 대한 메타적인 고민을 하는 것이 궁극적인 목적입니다.
목차
1. 쓸데없이 긴 맥락
Learnability 연구하는 다른 과정생의 research seminar에 갔다왔는데 생각했던 지점이 많아서 메모. (4월 20일에 돌아온다면서 글을 쓰고 있을 정도로 생각했던 지점이 많았다!)
언어학의 이론은 일련의 언어표현을 '설명'하는 것이 목표인데, 바로 이때 '설명'이란 게 뭐냐에 있어서 형식주의적 언어이론이 소위 '문법'과 다른 지점이 몇 가지가 있다.
촘스키가 1960년대 Aspects에서 제안하였기 때문에 촘스키의 Adequacy thesis 라고도 하는데, 이론의 목적은 3가지 '타당성'(Adequacy)을 충족하는 것이고, 이에 따라 언어학의 이론은 무슨 '문법'이라든가 '외국어배우는법'과 차별화된다.
- 관찰적 타당성: 모든 언어표현을 분류가능해야 한다
- 기술적 타당성: 형식적 기제를 통해 존재하는 모든 언어표현을 그리고 오직 존재하는 언어표현만 생성할 수 있어야 한다.
- 설명적 타당성: 개별언어와 무관하나, 적절한 변인설정을 함으로써 개별언어를 타당하게 기술할 수 있어야 한다1
다른언어가 존재하지 않는 양 단순히 특정언어에 딱맞춤인 이론은 쓸모없는 이론이다. 동물에 대한 이론을 구성하면서 오직 코끼리에만 집중하여 "동물은 코가 길다"라는 이론을 만든다면 그것은 오직 코끼리만 설명할 수 있을 뿐 동물 이론으로서는 쓸모가 없다.
설명적 타당성을 충족하기 위해 언어이론은 보편적 원리가 조작되는 방식을 통해 개별언어를 설명해야 한다.
이러한 측면에서 learnability 연구의 대상은 "특정 인종, 특정 언어문화권 그런 맥락과 상관없이 모두가 타고난 보편적 기제들이 언어데이터를 관찰/일반화하는 방식으로 조작되어서 목표언어를 생성하는 시스템이 되어가는 과정"이다.
보편적 원리: 인간이 공통적으로 가진 언어기관이, 형식적으로 어떤 기본값을 가지는가? (예: 가청+생산가능 주파수범위, 음소로 실현될 수 있는 자질합, 발음가능한 음소연쇄, 인지적으로 처리가능한 범위) 특히, 이 기본값은 기억-연상-사고 등 인간의 다른 심리/인지 메커니즘과 비교하여 어떻게 다르며, 다른 학습/기억 알고리즘 (예: 기계학습)과 어떻게 다르며, 그리고 다른 동물들의 의사소통 수단과 어떻게 다른가?
조작되는 방식: 모든 인간이 같은 언어기관을 타고 나는데, 언어가 다양하고 또 언어가 변화하는 데 이유가 되는 기제. 즉, 환경에 있는 언어데이터를 학습하여 보편적 기본값이 조작되어 바뀌어 현실 언어로 발현되는 알고리즘. 규칙기반 이론이라면, 규칙순의 변화(re-ordering)가 되겠고, 제약기반 이론이라면, 제약 간 서열 재정립(re-ranking) 혹은 개별제약의 가중치 변경이 될 것이다.
맥락은 여기까지만 하고, Research seminar에서 발표 들으면서 생각했던 지점들을 아래와 같이 메모한다. 이 과정생은 제약기반 이론의 맥락에서 각 제약의 가중치 변경이 어떻게 이루어지는지를 연구하는 사람이다.
2. Analytical mind vs learner
언어현상을 타입에 따라 분류하고 이 유형, 저 유형 이런식으로 pigeonhole (비둘기를 비둘기집에 넣듯 어디에든 집어넣기)하는 것은 분석적 정신(analytical mind)이다. 소위 '문법기술'이 이러한 것이다.
그러나 모든 분석이 학습의 대상이 되는 것이 아니다. 과도분석은 learnability study에서 의미가 없다.
과도분석의 예시들은 이렇다. "도대체", "어짜피" 가 사실 한자어이고 각각 都大體 於此彼로 쓴다는 것은, 알면 좋은 지식이지만 언어학습의 대상이 아니다 -- 그런거 몰라도 한국어 화자로서 결격사유가 되지 않는다.
"괜찮아" 가 "괘-ㄴ치 않아"로 분석되고, "괜하-2지 않아"라는 건 아래 밈이랑은 아무 상관이 없다. 상식적으로 "괜찮다"랑 "괜히"를 같은 어근을 공유하는 그룹으로 묶는 건, 형태소분석을 할 줄 아는 사람이 아니라면 좀 선넘는 것같다. 유식한 척 자랑하고 싶다면 머리속 언어공간 외에 다른 공간(임진왜란이 1592년에 일어났다는 지식과 같은 공간)에 넣어두면 좋지만, 그게 언어는 아닌 것이다.
어떤 표현들은 더 분석하는 것이 pedantic 할 따름이다. 이미 이 블로그에서 충분히 이야기한 것 같으니 여기까지만 적겠다.
만족할 만한 설명 그리고 전공자가 말하지 않는 이유
0. 요약어떤 게 '설명'으로 인정되는가에 대한 아주 짧은 단상입니다. 결국 설명보다 중요한 것은 어떤 질문을 할 수 있느냐가 아닐까요? 목차 1. 물고기와 불고기출처: https://www.threads.net/@tip_tip_
linguisting.tistory.com
반면, 어떤 언어의 모국어 화자가 되어가는 과정 속에서 이루어지는 데이터의 일반화가 있고, 그 일반화에 기반한 언어표현 생성이 있다. Learnability는 이것에 초점을 맞추어야 한다.
(여담: learner를 "학습자"로 번역하면 막 제2외국어 공부하는 사람같이 느껴지는데, learner는 사실 명령어의 집합이라든지 기계라든지 컴퓨터 프로그램 같은 거다. 언어데이터가 주어졌을 때, 형식주의적 기제들로 구성된 learner는 그걸 '학습'해 새로운 언어 표현 생성이 가능한 시스템으로 발전한다)
3. 제약 학습의 방법론
Gradual learning algorithm (Boersma 1997, Boersma & Hayes 2001)은 OT적 제약들을 기계학습하는 learner algorithm이다. 수많은 시행착오를 거치면서 차츰 제대로 된 언어표현을 생성하는 constraint weights를 찾아간다.
3단계로 이루어진다.
1단계: 제약들의 weights에 따라 기저형을 표면형으로 도출
2단계: 그 표면형이 실제 형태와 같은지 평가 (Boolean)
3단계: 평가결과에 따라 weights 조정.
(새로 조정된 제약군들을 가지고 다시 1단계 시작)
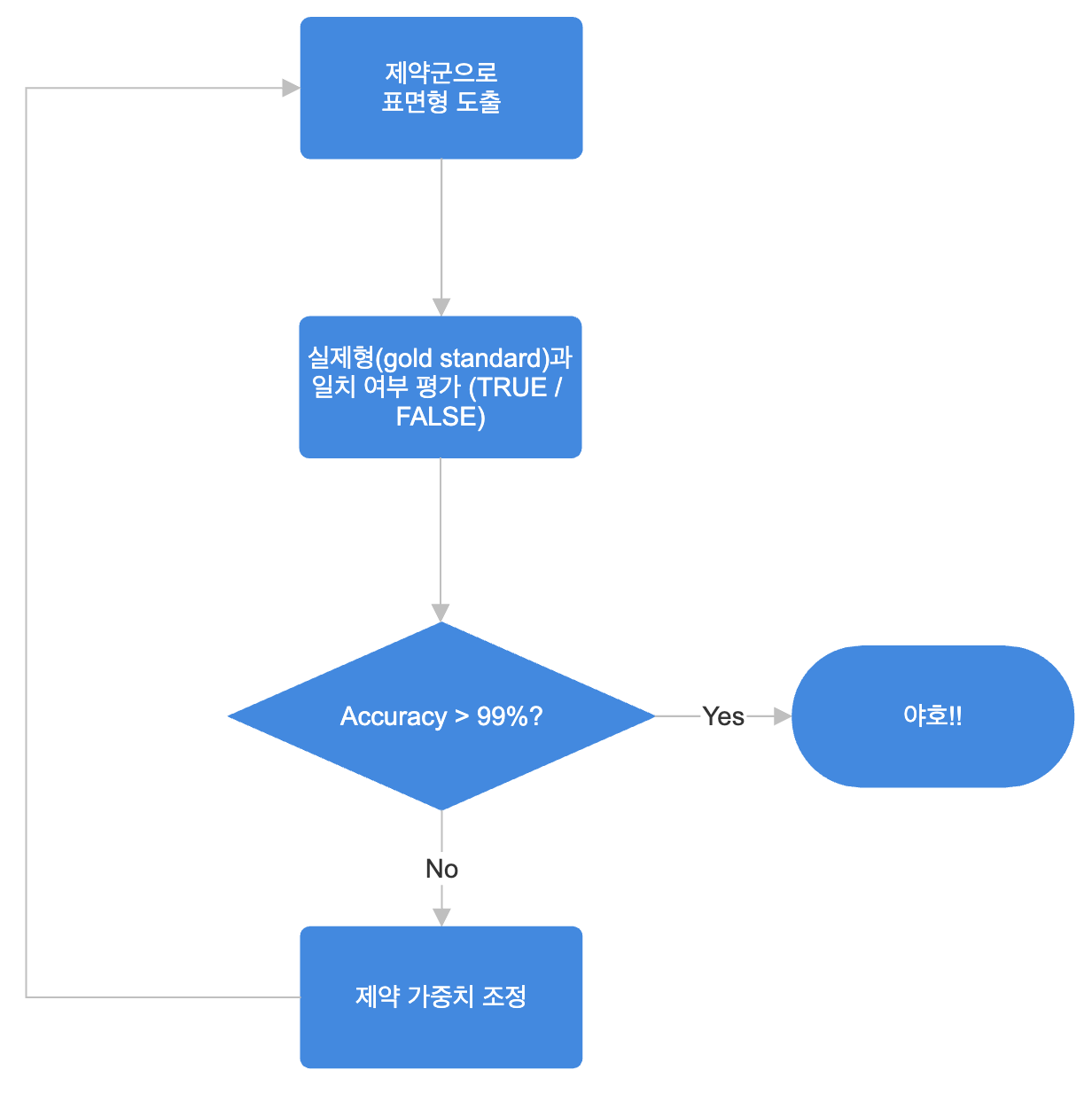
몇 가지 hyper-parameter setting 지점이 있다.
우선, 초기상태가 무엇인지다. 너무나 유명하지만 OT learnability 연구에서는 유표성제약이 충실성제약보다 항상 우위에 있다고 본다. 그런데 구체적으로 어떠한 초기상태를 설정할 것인지가 이론의 핵심이다. 빨간색 굵은 글씨를 쓴 이유를 잘 생각해보자. 이것이 바로 촘스키언에서는 Principles (parameters의 상대적 개념)이지 않을까? 그리고 아예 백지상태를 상정할 수 있는 기계학습 알고리즘과 비교했을 때, "사람이 가지는 편향(bias)"를 표현하는 방법이지 않을까?
두번째로 weights 조정 algorithm인데, 여기서 모든 게 갈리는 것같다. 그래서 매우 중요하다. 조정은 promotion과 demotion으로 이루어진다. promotion은 "만약 weight가 더 주어졌으면 올바른 표면형을 도출했었을" 제약에 더 가중치를 주는 것이고 demotion은 그 반대다. 그런데 제약들은 서로 독립적이지 않다는 게 모든 문제의 시작이다. 덩달아서 같이 promotion되기도 demotion되기도 한다. 왜냐면 한 제약이 다른제약의 superset이기도하고 어떤 제약은 다른 제약을 masking하기도, 상충하기도 하기 때문이다 (OT제약론은 아주 다른 분야고 파고들면 끝도없다).
결국 이 날의 research seminar는, 저 순서도를 엄청 돌리면서 어떤 소수점이하의 미세조정과 파라미터 설정이 언어데이터를 100% 도출했다 뭐 이런 내용이었다.
그리고 개인적으로 몇 가지 근본적인 (그래서 뭐 다된 밥에 재 뿌리자는 것도 아니고 질문하기 뭐한) 질문들이 떠올라서 메모한다.
3. 질문들
3.1 Accuracy 100%가 능사인가?
내가 가졌던 의문은 이런 것이었다.
어떻게든 engineering을 해서 100% 정확한 표면형을 도출하는 파라미터 세팅에 도달할 수 있다. 아니, 무슨 수를 써서라도 100%에 도달하겠다 하면 어떻게든 가능하다. 그렇게 해놓고 나중에 합리화를 하는 건 도대체 무슨 의미가 있는 걸까? 점수가 뭐가 중요한가?

사실 어떠한 일반화 (심지어는 규범주의적 '언어규정') 는 반드시 사실이 아닐 수 있다.
예를 들어 '전략'을 [절략]으로 발음하는 건 일반적이지 무슨 생리적인 이유에 따른것도 아니요, 반드시 모든 사람들이 그렇게 하는 것도 아니다. 그러면서 우리는 기계에게는 100% [절략]을 요구한다. 이게 문제가 되는 이유는, 역동적인 언어변화상을 고려하지 않는다는 데 있다. 정적인 언어는 없다. 어느 순간에도 언어는 변화하는 중이다. 화자의 accuracy는 결코 100%가 나오지 않는다. 자연적으로 존재하는 noise를 고려하지 않고 "와 100% 정확도 달성하는 알고리즘은 이러저러한 파라미터 세팅하니까 나온다! 연구 끝!" 이건 말이 안 된다.
3.2 이론적 논쟁의 장의 소멸
Learnability 연구들이 알고리즘의 기계적 구현으로 이루어지기 시작한 건 아마 내 세대 이전의 일일 것이다.
그래서 Research Seminar에서도 그저 본인이 어떻게 파라미터 구성을 했는지, 즉, 초기설정 그리고 평가 그리고 가중치 조정 알고리즘을 어떻게 구성했는지를 설명하는 데에서 그쳤다. "이러저러하니 성공했어요" 라는 내용의 발표라면 거기에 이론적으로 대화할 수 있는 부분은 없다.
심지어 제약이 수백개, 진짜 수백개에 달한다. OT Soft 안쓰고는 이 제약군이 제대로 된 형태를 도출하는지 아닌지 알 수가 없다. 고전적 OT에서 칠판위에 손으로 Tableaux 그려가면서 평가를 하고, 청중과 발표자가 제약서열을 이래저래 바꾸어가며 즉석에서 논쟁할 수 있는 장은 사라진지 오래다.
내가 이 생각을 발표장에서 유독 하게 된 이유는, OT 초창기 패러다임을 거의 멱살잡고 끌고왔고, 심지어 본 발표에서 몇 차례 인용도 된 권위자가 그냥 묵묵히 앉아있다가 질문도 없이 코멘트도 없이 가장 먼저 발표장을 떠나는 뒷모습을 보았기 때문이다. 어떤 질문은 아예 기반 자체를 흔드는 질문일 수 있다. 규칙기반 이론가가 OT 틀 자체를 질문할 수도 있다. 그러나 그런 질문 조차 하는 게 의미없는 발표가 있다. 좀 그런 발표였다.
어쨌든, 최근 OT learnability 연구의 추세가 다 이런 식으로 수백개의 제약을 컴퓨터 써서 가중치 설정하고 이런식이다보니까, 오히려 교실에서는 고전 OT만 하게되는 것같다. 마치 게임을 하듯 언어데이터를 고전 OT만으로 설명해보려고 하는 것이다. 약간 이런거다. "어짜피 HG나 가중치 제약 기반 이론 써서 어찌어찌 가중치 미세조정하면 설명될 것"이라는 last resort가 있는데, 그게 너무 기믹인 것이다. 그래서 재미가 없다.
3.3 수학처럼 딱딱 떨어지는, 그러나 그냥 숫자놀음이 되어버린
음운론 수업을 들었는데 그게 수학처럼 딱딱 떨어지는 거에요
그래서 거기에서 흥미를 느낀 것 같아요
시쳇말로 최근 이론음운론 필드를 떠나는 사람들이 많은 이유에 대해, 필드 떠나는 사람들은 (1) "미세조정으로 뭐든 가능하다"는 자각을 하고, (2) 흥미를 잃고, (3) 용기가 있는 3박자를 갖추었다고 한다.
3번을 갖추지 못하여 "미세조정으로 뭐든 가능하다는 걸 알고 흥미를 잃었으나 떠날 용기가 없다" 이런 사람들은 비굴하게 필드에 빌붙어서 연명할 뿐이고,
2번을 갖추지 못하여 "미세조정으로 뭐든 가능하다는 걸 알게 되었음에도 흥미가 사라지지 않는다"라면 그건 애초에 이론음운론자가 아니었던 것이고,
1번도 갖추지 못하여 아예 "파라미터 미세조정으로 뭐든 설명이 된다는 걸 모른다"라면 애초에 공부할 정도의 머리가 되지 않는 것이라 한다. 🤣🤣🤣
떠나지 않는 나는 어떠한가? 비굴한가, 음운론 연구자가 아닌가, 머리가 나쁜가?
머리가 나쁜 것은 맞지만, 음운론을 계속할 정도로만 나쁘고 (1)을 모를 정도로 나쁘지는 않다. 난 (1)에서 오히려 고무되는 것같다. 그런의미에서 애초에 이론음운론 연구자가 아니었을지도 모른다. 근데 어짜피 레이블은 허상이라는 게 내 연구주제 아닌가....
마법사처럼 데이터 슥 보고 제약서열 뙇 내놓는 사람들이 멋져보였지만, 난 마법사가 아닌 머글이었다. 그래서 늘 기계적으로 할 수 있지 않을까, 그리고 할 수 있어야 한다를 생각해왔다.
나뿐만이 아니다. 일련의 사람들이 있다. 그런 사람들이 Praat을 만들고, '더블클릭해서 "언어"를 실행하시오 (language as an executable)' 따위의 생각을 하고, 이상적인 자연언어 모델은 형식단위의 기계적 조합으로 (그리고 기계적 조합이기에 기계적으로 가능한) 설명되어야 한다고 믿는다. 당연한 귀결은 베이지안하게 언어이론이 '자동으로' 나오는 것이다.
4. 무엇을 할 것인가?
내 생각은 이렇다. 궁극적으로 이론 연구자의 과업은 어떤 질문에 '예쁘게 대답'하는 것이 아니라 "새로운 질문을 하고 거기에 거칠게 대답하는 것"이어야 한다. 질문을 던지면 대답은 미세조정으로 어떻게든 나온다. 물론 그 미세조정을 시행착오를 거치면서 하고, 그 미세조정치의 합당함을 설명하는 것이 이론가의 몫이다.
천체물리학자 Neil deGrasse Tyson는 생성형AI를 두고 이렇게 말한 적이 있다. "챗GPT는 누군가의 이름을 붙이기 애매한 정도의 수준의 글까지만 쓸수 있다." 사용 매뉴얼, documentation, 레시피, 어디 찾아가는 길, 백과사전 항목. 이런 것들은 누구 이름이 붙지 않는다. 그러나 새로운 그래서 논란이 되는 생각을 담은 논문은 반드시 누군가의 이름이 붙는다. 챗GPT는 후자를 쓸 수 없다. 연구자는 후자를 써야한다.
소위 '컴퓨터가 다 해줄꺼야'라는 낙관을 다른 관점에서도 생각해볼 수 있다.
(1) "미세조정으로 뭐든 가능하다"라는 기계적 낙관은, 일면 생성주의가 태동되던 1960년대의 언어학계 풍경을 닮았다. 촘스키가 1960년대 생성이론이 태동하던 시기를 여러 인터뷰에서 묘사했는데, 컴퓨터✨ 라는 신문물이 대학에 보급되던 당시 구조주의 막판의 풍토가 딱 이랬다고 한다. 연구자들 사이에서는 "이제는 컴퓨터로 모든 게 다 가능하다" 라든지 "이제 언어학자의 일은 자연언어를 최대한 다양하고 정확하게 전사하고 컴퓨터에 집어넣는 일 뿐이구나" 라는 분위기였다고 한다. 그러나 모두가 알다시피 패러다임이 바뀌었다.
어쩌면 우리는 한 시대의 마지막을 살고 있는지도 모른다. 촘스키의 건강이 요즘 예전같지 않다고 한다. 높은 확률로 우리는 더 이상 촘스키의 새로운 말을 듣지 못할 것이다. 어쩌면 이 시점에 제2의 촘스키가 나타나 모든 걸 뒤집어 엎는 일이 생길까?
- 글이 유익했다면 후원해주세요 (최소100원). 투네이션 || BuyMeACoffee (해외카드필요)
- 아래 댓글창이 열려있습니다. 로그인 없이도 댓글 다실 수 있습니다.
- 글과 관련된 것, 혹은 글을 읽고 궁금한 것이라면 무엇이든 댓글을 달아주세요.
- 반박이나 오류 수정을 특히 환영합니다.
- 로그인 없이 비밀글을 다시면, 거기에 답변이 달려도 보실 수 없습니다. 답변을 받기 원하시는 이메일 주소 등을 비밀글로 남겨주시면 이메일로 답변드리겠습니다.
'생각나는대로' 카테고리의 다른 글
| role-rule merger? (0) | 2025.02.27 |
|---|---|
| '-습니다'와 '-읍니다' (0) | 2025.02.23 |
| a couple of 에서 자꾸 of 생략하기 (4) | 2025.02.12 |
| mfm31 fringe meeting 'sublexica across languages' (2) | 2025.02.09 |
| 폰트와 스타일의 문제 (3) | 2025.02.04 |