0. 요약
Montreal Forced Aligner를 이용한 Forced alignment를 대규모로 하다가 문제에 봉착했다.
큰 소리로 생각한다는 개념으로 나의 생각 과정을 여기에 적는다.

목차
1. 이슈
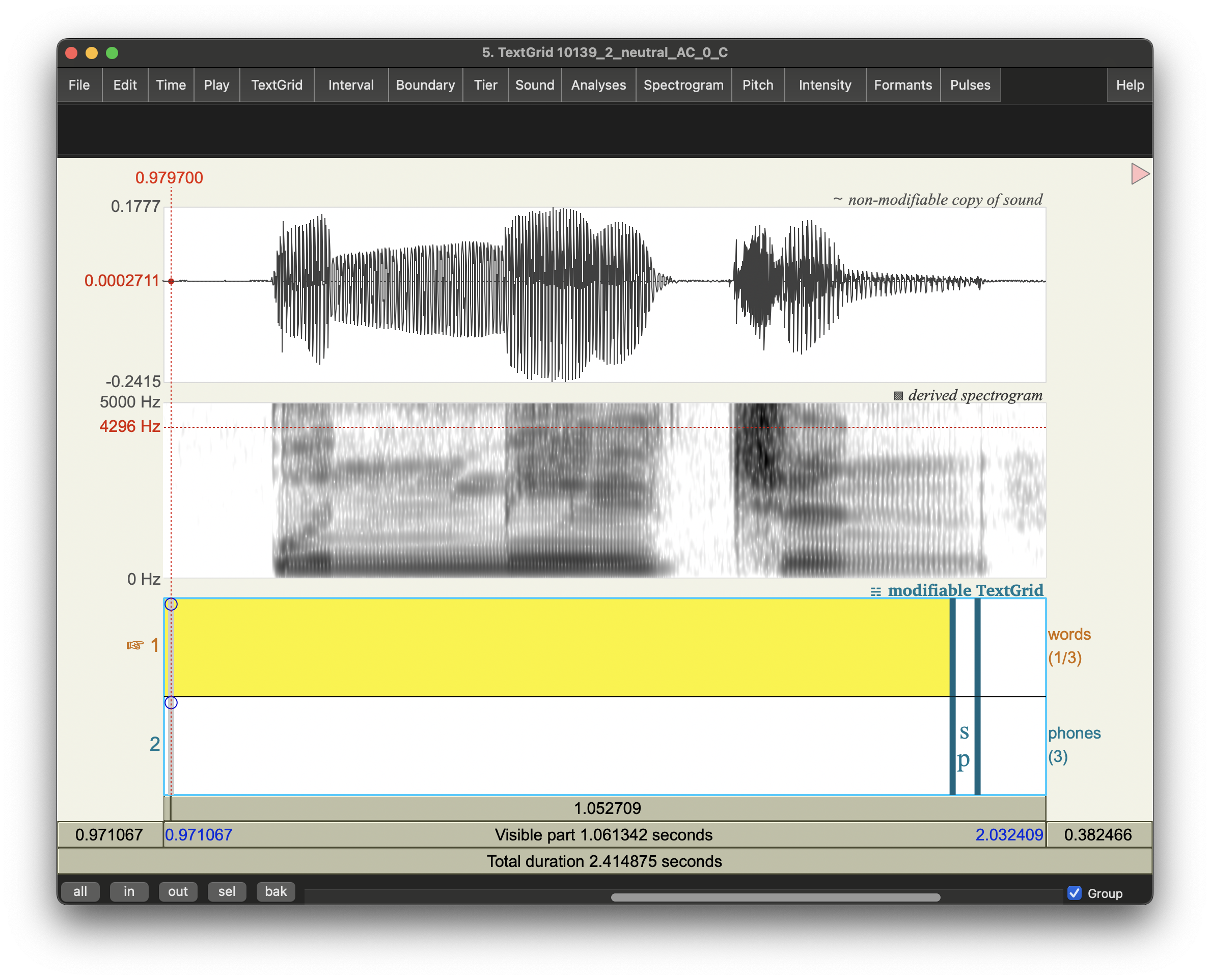
각 wav 녹음파일에 대하여 stimulus (화면에 표시된 한국어 단어)의 내용 (한글철자)을 유일한 tier로 가지는 praat textgrid를 python script를 이용하여 생성했다.
"[participant ID]_[base id]_[phonotactics]_[manipulation]_[repetition]_[group].wav" 형식의 wav 파일명을 parsing하여 base_id와 phonotactics 값에 따라 해당하는 단어의 철자형을 TSV 형식의 stimuli list 로부터 읽어와 textgrid를 만들었다.
그러나 이렇게 생성한 textgrid 파일을 상응하는 wav 파일과 pairing해서 MFA align 돌렸을 때 모든 단어가 spn (알수없음)이 되었다.
2. 시도한 해결책
우선 비-ascii 문자인 한글을 사용한다는 부담이 있었기 때문에 NFC방식 NFD방식 혼재되어, (겉보기에는 같으나) 발음사전의 등재형과 textgrid 각각에 들어있는 한글철자형이 같게 인식되지 않았다고 생각했다. 이 문제를 의심한 이유는, 발음사전 만들기와 textgrid 생성은 Windows machine에서 했고, MFA 돌리는 건 맥북프로에서 했기 때문이다.
2023.08.19 - Mac에서 받은 파일 한글 깨짐 해결
그래서 아예 한 시스템에서 처음부터 모든 작업을 다시 해보았다. 즉, 맥북에서 발음사전 만드는 스크립트와 textgrid 생성 스크립트를 돌리고 다시 MFA align했다. 문제는 해소되지 않았다.
MFA에서 제공하는 MFA validate 를 사전과 코퍼스(wav파일목록) 모두에 실시해보았다. 에러는 없는 것 같았다.
3. 진짜 원인: 호환 안 되는 기호체계
진짜 문제는 사소한 데(?)에 있었다. 바로, 전사 기호 체계의 문제.
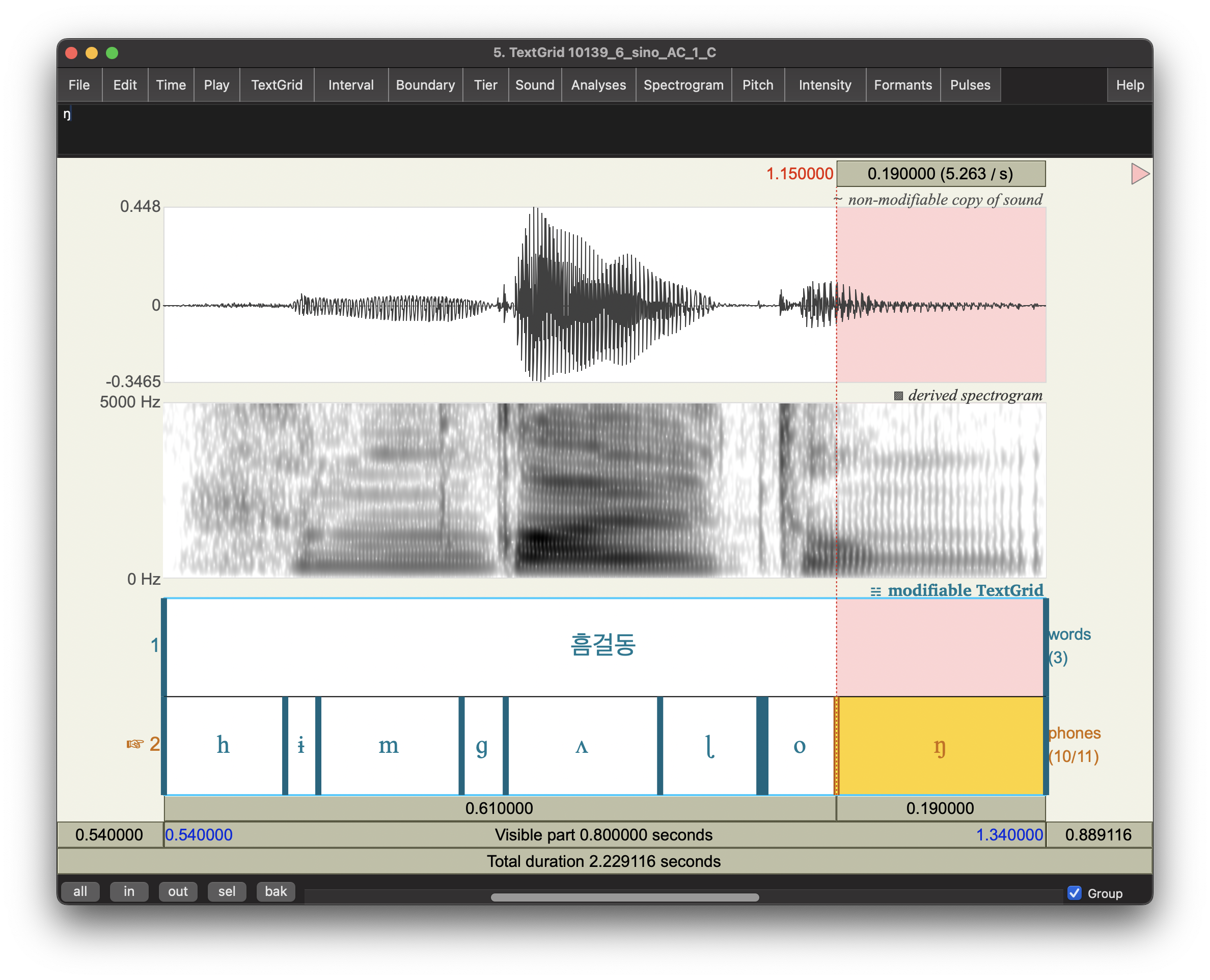
첫째로, MFA의 acoustic model은 활음을 개별 단위로 보았으나, 내가 만든 발음사전은 이중모음(반모음+모음)을 개별단위로 올려놓았기 때문이다.
예컨대, "예시"라는 단어의 발음을 나는 발음사전에 [jɛ sʰ i] 이렇게 3개의 단위로 등재해놓았으나, MFA의 acoustic model의 전사 시스템에선 [jɛ]라는 단위는 없다. 따라서 [j ɛ sʰ i] 이렇게 4개의 개별단위로 구성된 발음으로 등재했어야 하는 것이다. (참고로 MFA Documentation 등에서는 phoneme이라는 용어 등을 최대한 피하려고 한다. 이해가 간다. 그리고 [tɕ] 와 같은 앞구르기하며 봐도 1개 단위여야 하는 소리들이 있기 때문에, 단위는 space-delimited여야 한다.)
따라서 이중모음이 들어간 모든 단어들은 MFA 입장에서는 "알수없는 발음"인 것이고 forced align할 수 없었던 것이다.
이중모음/반모음 문제에 대한 예전 글이 마침 있어서 링크를 달아본다.
2023.09.21 - 김경아 "한국어 음운론" 의 이중모음 활음 반모음
뿐만 아니라 ㄹ의 전사 과정에서도 같은 문제가 있었다. 발음사전에서 나는 retroflex [ɭ]을 써야할 맥락에 평범한(?) [l]을 썼고 그래서 인식이 안 되었던 것이다.
MFA에서는 한국어 liquid ㄹ에 대하여 flap [ɾ], palatalized [ʎ], 그리고 retroflex [ɭ]을 사용한다. 내가 오래전 처음에 MFA가 탐재한 한국어 acoustic model을 분석하면서 기술한 사용 분포는 아래와 같다.
[ʎ]: _C, OR _l (as [ʎʎ])
[ɾ]: V_V
[ɭ]: Elsewhere
그래서 아마도 나는 "미친 무슨 retroflex가 elsewhere (default realization) 냐. 과거의 나 제정신 아니었군." 하는 생각에 과거의 나를 믿지 못하고 당연히 상식적인 선택을 한 것이다. 아니 대체 한국어 liquid의 실현 중 retroflex가 가장 분포가 넓다는 미친 주장을 누가 한다는 건가? (MFA가 한다)
그래서 반모음/활음 부분 수정할 때, ㄹ 전사 부분도 수정했다.
여기까지 하고 다시 mfa align 돌리니 대성공!
3.1 도움이 된 디버깅 과정
이걸 깨달아가는 과정에서 교훈을 얻었다.
3.1.1 Documentation 열독하기
먼저 오류의 원인을 찾아가는 과정에서 MFA documentation을 세세하게 읽어보았다. 특히 'all commands' 섹션이 많은 도움이 되었다.1 여태까지는 MFA 쓸 때 내가 과거에 사용했던 command를 그대로 parameter값만 바꾸어 재활용했는데, 이제부터는 아예 MFA documentation을 화면에 켜놓고 작업해야겠다.
어쨌든 documentation을 보면서 우선 이 부분에서 내 발음사전 포맷이 잘못되어 있음을 처음 느꼈다.
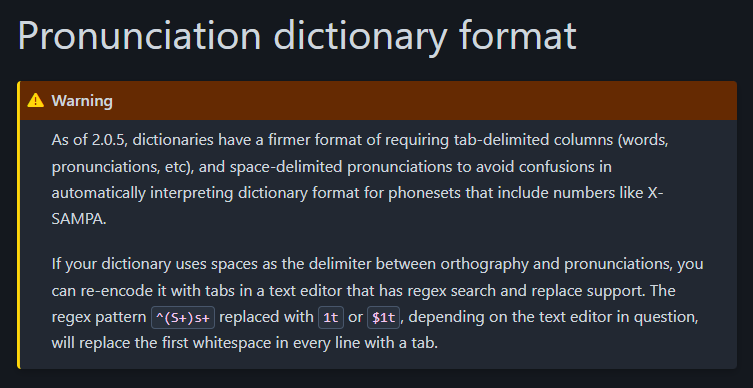
내가 MFA를 처음 썼던 것이 꽤 시간이 지났고, 그 사이 버전 업데이트를 두 번인가 했다. 그러나 발음사전 형식은 내가 옛날 옛적에 만든 그 형식을 답습하고만 있었다. 그래서 철자형과 발음형 사이에 space 네칸으로 띄어져있는 형식이었고 tab-delimited되어있지 않았다. 물론 업데이트할 때 release notes를 제대로 봤으면 깨닫고 형식을 고쳤을텐데, 그러지도 않았다. 옛 format의 발음사전이 문제 없었던 건 그냥 backward compatibility를 고려해주었기 때문이지, 안 되었어도 탓할 수 없다.
하지만 이미 앞에서 다 적었듯이 발음사전에 space를 썼니 tab을 썼니가 문제의 진짜 원인은 아니었다.
3.1.2 verbose
mfa align 하면서 verbose flag 를 써서 아래와 같이 문제 해결의 결정적 힌트를 얻었다.

"There were 288 pronunciations in the dictionary that were ignored for containing one of 7 phones not present in the trained acoustic model."
나는 발음사전을 만들 때 acoustic model에 사용된 전사 체계를 엄밀하게 따랐기 때문에 절대 위와 같은 오류가 나서는 안 되었다. MFA에서는 WARNING으로 분류할 수 있지만, 나의 경우는 발음사전을 의도적으로 구성했기 때문에 ERROR이다. 또한 그런 기호가 한 두개도 아니고 7개나 된 다는 것 역시 red flag.
그런데 바보같이 처음 했었던 생각은 내 발음사전 전사체계에 사용된 기호에 잡음(?)이 껴서, 예컨대 space 하나 더 들어가서, 오류가 난 것일지도 모르겠다는 것이었다.
그놈의 "잡음" 확인하기 위해 mfa model inspect dictionary command랑 mfa model inspect acoustic command 써서 그 출력값을 갖고 acousitc model에 사용된 symbol set과 내 발음사전에 있는 symbol set을 대조해보다가 이중모음 부분에서 아차했다.
결국 어느 디버깅의 과정도 그러하듯이, 답을 알고나면 사소하다. 다만 그 과정이 깊은 독에 물을 붓는 것과 같을 뿐.
다음 섹션부터는 상당히 장황한 이야기가 이어진다. 소리내서 생각하는 부분인데, 대체로 textgrid의 생성과정에 문제가 있다고 '잘못 추측'하는 내용이다. 그러나 사실 문제는 발음사전에 있었다.
4. 맥락과 장황한 과정 이야기 (소리내서 생각하는 부분)
실험 녹음 데이터 수집한 것 MFA 돌리기 위해서, 나는 음향파일을 제외하고 다음 3요소가 필요하다.
1. Base textgrid: 지금 이 파일이 무슨 단어를 발음한 건지 (철자형으로) 알려줌.
2. MFA 발음사전: 철자형과 phonetic symbols 사이의 대응표.
3. MFA 음향모델: 각 phonetic symbol이 어떤 음향자질을 가지는지
그러니까 MFA가 Forced align하는 과정을 아주 이해하기 쉽게 비유해서 말하면 1을 보고 2에서 그 단어의 발음이 어떤 소리들로 구성되는지 찾아본 다음, 3을 가지고 그 소리들을 가장 그럴듯한 위치에 배열하는 것이다.
예를들자면, "아빠"라는 단어를 녹음한 파일 appa.wav가 있다고 치자. 그리고 task는 이 음성파일에 "아빠"의 발음인 [a p* a]를 forced align 하는 것이다.
1. Base textgrid에서는 음성파일에 대응하는 "아빠"라는 레이블을 달아준다. appa.wav랑 대응될 수 있게 appa.textgrid로 만들어준다.
2. MFA 발음사전에서는 "아빠 a p* a" 라는 한 줄이 들어가있다. 이것은 아빠라는 단어의 발음이 [a p* a]라는 걸 알려준다.
3. MFA 음향모델은 거칠게 말하자면, 음향음성학에서 가르치는 내용이 들어있다. [a]의 F1 F2값과, p*라면 burst 지점이 있고 어중 silent 구간이 있고 등등.
MFA는 이 정보들을 가지고 wav파일에서 a처럼 생긴 스펙트럼 구간에 [a] duration을 마킹하고 뒤이어 [p*] duration을 마킹한 다음 이어서 [a] 조음이라 추정되는 구간에 마킹한다.
나의 문제는 Base textgrid 생성에 있다.
실험단어가 무척 다양했기 때문에 type별로 일일이 textgrid 만드는 게 불가능하고 token도 6000개에 달한다. 따라서 스크립트를 이용해서 생성해야 한다.
pilot 분석할 때에는, type이 하나였기 때문에 Eleanor Chodroff 선생님이 짠 praat script를 이용했다.
나는 [이 링크]에서 다운로드했는데, 현재는 링크가 죽은 듯하여 여기에 다시 옮겨온다.
# create_textgrid_mfa_simple.praat
# Written by E. Chodroff
# Oct 23 2018
# This script takes as input a directory containing wav files and
# outputs TextGrids with a single tier called "utt" (for utterance)
# and a single interval with the text of the transcript.
# The first boundary is currently set at 200 ms from the start.
# The second and final boundary is currently set at 500 ms from the end.
### CHANGE ME!
# directory with wav files that need TextGrids
dir$ = "/Users/Dissertation/Korean experiment"
# text of transcript
text$ = "여기에단어를입력"
###
## Maybe change me
# insert initial boundary 10 ms from start of file
boundary_start = 0.010
# insert final boundary 10 ms from end of file
boundary_end = 0.010
##
writeInfo: dir$
Create Strings as file list: "files", dir$ + "*.wav"
nFiles = Get number of strings
appendInfo: nFiles
for i from 1 to nFiles
selectObject: "Strings files"
filename$ = Get string: i
basename$ = filename$ - ".wav"
Read from file: dir$ + basename$ + ".wav"
dur = Get total duration
To TextGrid: "utt", ""
Insert boundary: 1, boundary_start
Insert boundary: 1, dur-boundary_end
Set interval text: 1, 2, text$
Save as text file: dir$ + basename$ + ".TextGrid"
appendInfo: " saved"
appendInfo: basename$
appendInfo: dir$ + basename$ + ".TextGrid"
select all
minusObject: "Strings files"
Remove
endfor
한 단어일 때는 문제없이 textgrid 생성과 발음사전 만들기 모두 잘 되었다.
그러나 문제는 pilot을 끝내고 실전(?)에 도입했을 때 발생했다.
실험단어의 종류가 많기 때문에 각각의 type에 대해 다른 base textgrid를 만들어야 했는데, 내가 그 정도의 praat scripting 능력은 없었다. 대신 나는 Python을 쓰고, praat textgrid 다루는 Python library도 있는 듯하여 Python으로 코드를 짰다.
애초에 PCT 일을 하면서 textgrid fotmat을 다룰 일이 있어서 자신이 있기도 했다. 복잡해보여도 textgrid format도 그냥 json-like 아닌가!
어쨌든 시놉시스는, wav파일명에 이미 메타정보를 다 포함되어 있으므로, 파일명을 파싱하여서 textgrid 생성하고, wav파일명과 동일한 .textgrid 파일로 export하는 것이었다. 뚝딱뚝딱 아래의 스크립트를 만들었다. 그리고 겉보기엔 잘 작동했다.
## This python script generates a textgrid file that can be used for Montreal Forced Aligner 2.
## Specifically, it creates a word level tier based on the name of .wav file e.g., "15_neutral_BD_0_C_10917.wav"
## It refers to the word list .xlsx file for the content of the word-level tier.
##
## pip install textgrid
## pip install pydub
import os
import sys
import textgrid
from pydub import AudioSegment
from pydub.silence import split_on_silence
import tkinter as tk
from tkinter import filedialog
def create_textgrid(txt_content: str, wav_file_path: str) -> None:
# The heart of this script. create textgrid with a tier of txt_content.
audio = AudioSegment.from_wav(wav_file_path) # Read the .wav file
silence_duration = 0.1 # silence to pad in the tier (in seconds)
tg = textgrid.TextGrid() # empty textgrid to work on
# Create a single tier for the TextGrid
tier = textgrid.IntervalTier(name='word', maxTime=audio.duration_seconds)
start_time = silence_duration
end_time = audio.duration_seconds - silence_duration
tier.addInterval(textgrid.Interval(start_time, end_time, txt_content)) # write an interval
tg.append(tier) # add the tier to the TextGrid
# Save the TextGrid to the output path
output_filename = os.path.splitext(os.path.basename(wav_file_path))[0] + '.TextGrid'
wav_dir = os.path.dirname(wav_file_path)
tg.write(os.path.join(wav_dir, output_filename))
print(f"Successfully generated TextGrid {output_filename}")
def parse_filename(filename: str) -> (int, str):
# parse a filename and return the base word id# and phonotactics.
parts = filename.split('_')
try:
# assumed filename convention: [participant ID]_[base id]_[phonotactic]_[manipulation]_[repetition]_[group].wav
base_id = int(parts[1])
phonotactics = str(parts[2])
except ValueError:
# filename convention: [base id]_[phonotactic]_[manipulation]_[repetition]_[group]_[participant ID]
base_id = int(parts[0])
phonotactics = str(parts[1])
return base_id, phonotactics
def locate_stimulus(id: int, phonotactics: str, stimuli: dict) -> str:
# using the base id number and phonotactics, locate the word that was recorded from stimuli_dict
try:
return stimuli[str(id)][phonotactics]
except KeyError:
input(f"Hey, something's wrong. base id {id} and phonotactics {phonotactics} is missing. (Enter to continue)")
return ''
def load_stimuli(file_path: str) -> dict:
stimuli = {}
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
header = lines[0].strip().split('\t')
for line in lines[1:]:
row = line.strip().split('\t')
id_value = row[0]
stimuli[id_value] = {header[i]: row[i] for i in range(len(header))}
return stimuli
def path_selector(pathtype='file') -> str:
root = tk.Tk()
root.withdraw()
while True:
if pathtype == 'file':
selected_path = filedialog.askopenfilename(title="Select Experiment Stimuli List")
if selected_path and os.path.isfile(selected_path):
break
elif pathtype == 'dir':
selected_path = filedialog.askdirectory(title="Select wav file folder")
if selected_path and os.path.isdir(selected_path):
break
root.destroy()
return selected_path
def main():
# use file selector to decide paths to stimuli list file and wav file directory
wordlist_path = path_selector('file')
wav_dir = path_selector('dir')
# get names of all wav files in wav_dir
wav_files = [f for f in os.listdir(wav_dir) if f.endswith('.wav')]
# load word list file
stimuli_data = load_stimuli(wordlist_path)
for file in wav_files:
# for each wav file, write textgrid and save the textgrid to wav_dir
id, phonotactics = parse_filename(file) # first, parse the filename to get base word id# and phonoatctics
# txt_content: the string to be contained in the textgrid tier
txt_content = locate_stimulus(id, phonotactics, stimuli_data)
create_textgrid(txt_content, os.path.join(wav_dir, file))
근데 Forced alignment 결과, MFA가 전혀 전혀!! 일을 하지 않았다. "뭔가 문제가 있는 것 같다"는 식의 error message도 없이 뚜껑 열어보니 아래와 같은 "쓰레기" 들만 가득했다.
판도라 상자 여는 기분으로 지도교수 미팅시간에 같이 열었는데, 이꼴이어서 내 얼굴이 아주 홍당무가 되었을 거다.
😡😡😡
추측하기로는 NFD NFC 차이 문제인 것 같기도 하다. 왜냐면 textgrid의 생성은 윈도우 머신에서 했고 MFA는 맥에서 돌렸기 때문. (어째 집에 거치된 윈도우 PC보다 들고다니는 맥북이 빠르다🤣)
그러나 추측일 뿐 아직 정확한 원인을 모르겠다. 아무래도 textgrid 만드는 과정부터 맥북에서 다시 차근차근 돌려야겠다. 아니면 NFC든 NFD든 한 방식으로 강제하는 것도 고려할 만할 듯.
- 아래에 댓글창이 열려있습니다. 로그인 없이도 댓글 다실 수 있습니다.
- 글과 관련된 것, 혹은 글을 읽고 궁금한 것이라면 무엇이든 댓글을 달아주세요.
- 반박이나 오류 수정을 특히 환영합니다.
- 로그인 없이 비밀글을 다시면, 거기에 답변이 달려도 보실 수 없습니다. 답변을 받기 원하시는 이메일 주소 등을 비밀글로 남겨주시면 이메일로 답변드리겠습니다.
- 나도 documentation을 해본 적이 있지만, MFA의 documentation은 읽기 쉽게 만들기 위하여 상당히 공을 많이 들인 티가 난다. [본문으로]
'Bouncing ideas 생각 작업실 > exp sharing 경험.실험 나누기' 카테고리의 다른 글
| fairseq translation task cross-attention 접근 쉽게하기 (0) | 2024.04.10 |
|---|---|
| Never assume anything (0) | 2024.04.02 |
| Fairseq transformer model에서 attention 뽑아내기 (2) | 2024.03.08 |
| 'JKDY' 테스트 돌리기 + 배포🎉 (2) | 2024.02.23 |
| 좌충우돌 딥러닝을 이용한 한글IPA변환기 (0) | 2024.02.20 |