0. 들어가기에 앞서
사용한 Montreal Forced Aligner 버전: 2.2.15
사용한 Korean Acoustic Model: korean_mfa (Version 2.0.0rc4.dev19+ged818cb.d20220404
사용한 Korean pronunciation dictionary: korean_mfa
음성녹음이 있다. Praat에서 음향분석하려고 한다. 가장 처음 해야 하는 일은 annotation을 하는 것이다. 근데, 음운론자로서 음향분석 그 자체가 목적이 아니라면, 손으로 다 annotation하는 건 정말 귀찮고 골치아픈 일이다. 이제 손으로 다 하지말고 언어모델의 도움을 받아서 빨리빨리하자. 이건 Montreal Forced Alginer로 한국어 forced align하는 팁이다. 본론은 3. 에서 시작. 앞으로 종종 업데이트 될 글이다.
2024-05-29 추가: 감사하게도 AHTOH (안똔)님께서 이걸 시도해보시고 막히는 부분 + 해결책을 포스팅해주셨다. [블로그 링크] 아무래도 Kaldy와 MFA 버전 호환 문제인 것 같다. 또한 공교롭게도! 2.2.15이 불안정하여 아예 서비스 중단된 상황이고 2.2.17이 stable version. conda forge에서 MFA 버전을 2.2.17으로 고정하도록 명령어를 수정했다.
목차
1. 통상적인 음향분석 준비과정
음운론을 하는 방식은 여러가지지만, 이제 많은 이론언어학자들도 스스로 음성을 수집해서 분석하는 시대가 되었다. 통사론은 모르겠는데 적어도 이론음운론자들 중 많은 사람들이 arm chair에서 일어났다.1 바로 praat의 보급 덕분이다. 매우 안정적인 이 프로그램 덕분에 이제 음성녹음만 있으면 쉽게 음향분석할 수 있다. 거짓말이다, 앞문장에서 밑줄로 적은 부분은 거짓말이다. (자동차가 "자동"으로 간다는 것, 분명히 기사아저씨가 들어가 있는데 택시가 "빈차"라는 것과 같은 수준의 언어도단이다🤣)
음성녹음만 있어서는 안되고, 그것을 praat으로 annotation부터 해야한다. 그리고 그 annotation을 기반으로 음향분석을 할 수 있다. annotation은 아래와 같은 걸 말한다.
여기 말소리가 있다. 이게 출발점이다2↓

annotation은 이 출발점을 가져다가 아래↓와 같은 '분석가능한 상태'로 만드는 걸 의미한다.

맞다. 이것은 그 유명한 "수학처럼 딱딱" 음성이다.[링크]
맨 위의 그림만 보고 눈치챈 사람이 있다면 엄청난 내공의 음성학자겠다. 여담인데, 음성학 전공하는 친구가 spectrogram 보고 단어 맞추는 게임을 심심풀이로 하는거 보고 기함을 했던 기억이 있다. 🤣🤣
https://nascl.rc.nau.edu/gramle/
Gramle
nascl.rc.nau.edu

그러나 나와 같은 머글들은 스펙트로그램을 날것으로 보고 있으면 골치가 아프므로 annotation을 해야 한다.
이 음성파일은 자연발화 말뭉치인 서울코퍼스의 일부인데, 9명의 연구원들이 직접 손으로 확인했다고 한다. (물론 2015년 역시 우가우가 시대가 아니기에 forced aligned된 결과를 realign함.)

이렇게 분석가능한 단위로 쪼개어지면, 구간 분석(duration analysis)과 포먼트 분석(formant analysis) 등을 할 수 있다. 구간 분석은 VOT가 어떻게 구현되었느니, 모음 장단이 어떻게 구현되었느니 등이 해당하고, 포먼트 분석은 말그대로 모음을 포함한 공명음에서 포먼트가 어떻게 실현되었나를 보는 것이다.
그런데 문제는 바로 이 "분석가능한 단위로 쪼개기"다. 내가 들었던 음향음성학 수업은 전부 스펙트로그램을 보고 수작업으로 직접 자모음을 분절해내는 annotation 훈련을 하는 과정이었다. (그건 내가 음성학자가 아니라 음운론자기 때문일 것이다.) 그런데 손으로 annotation하는 건 문제가 많다.
- 나는 음성학자가 아니라서 책을 참고하면서 해야 겨우겨우 할 수 있고, 여러사람이 하면 일관적이지 않을 수 있다.
- 또 나처럼 권위가 없는 사람이 annotate한 textgrid를 사람들이 믿어줄 리가 없다.
- 귀찮고 성가시고 시간이 오래걸리고 지루하다. 그래서 연구자들의 삶의 질 하락의 주범이 된다.
- 너무 오랫동안 컴퓨터로 반복작업을 하면 손목과 허리가 아프다. 그러면 마찬가지로 연구자들 삶의 질이 하락한다.
이 네가지 이유 때문에 그래서 언어모델을 사용한 forced alignment를 할 줄 알면 좋다. 기계에게 모든 일을 맡기면 언어학자들이 실직자가 되므로 (그거 아님) 귀찮은 부분만 기계에 맡기자.
애초에 annotation은 일관성이 있야 하고 정확해야 한다. 다시 말하자면 이것은 매우 기계적인 작업이다. 기계적인 작업은 사람이 아닌 기계가 하는 것이 윤리적으로 옳다. (이거 어디서 읽어본 것 같다는 생각이 든다면, 이 글이 출처다.)
2. Forced aligner
이 포스팅에서는 Montreal Forced Aligner를 사용하지만, 이외에도 말소리를 세세하게 나눠주는 다양한 툴이 있다. 생각나는 대로 주요 Forced aligner를 시대순으로 나열해보자.
2.1 Penn Phonetics Lab Forced Aligner
Penn Phonetics Lab Forced Aligner (줄여서 P2FA)는 2008년에 발표되고 2009년까지 유지보수되어온 Forced alginer이다. HTK 기반이고 Python 2로 짜여져있다.
2.1.1 P2FA에서 파생된 Korean Phonetic Aligner
Korean Phonetic Aligner는 Penn Aligner처럼 HTK 기반이다. [홈페이지]에 들어가서 음성파일과 한글 transcription을 업로드하면 forced align된 결과를 받을 수 있게 되어있다.
2.2 Montreal Forced Aligner
이 글에서 소개하는 툴킷이므로 더 이상의 소개는 생략한다. [홈페이지]
2.3 Charsiu
Charsiu는 신경망 모델을 이용해서 텍스트 없이 음성파일만 있으면 자동으로 전사+forced align해주는 툴이다. 현재로서는 미국영어와 보통화(Mandarin Chinese) 모델만 나와있는데, 차차 다른 언어의 charsiu 모델도 나오게 된다면 활용성이 좋을듯.
사실 Charsiu는 叉燒의 광동어 발음인데, 맛있는 광동지방 고기요리다. 기름진 돼지고기 부위를 양념하고 바비큐해서 만듦. 일본 라면에 들어가는 '차슈'도 이것의 일종이다. (설마 정말 요리명에서 따왔나 했는데, 정말이라고 한다)
3. MFA 실습
이번 섹션에서는 본인의 컴퓨터를 이용하여 Montreal Forced Aligner를 사용하는 방법을 차례대로 소개한다.
3.1 준비

3.1.1 각자 준비해올 것: conda, praat
일단 각자 집에서 준비해와야 하는 준비물이 있다. conda랑 praat이다. 음성파일과 기초전사는 하단에서 제공해준다. Montreal Forced Aligner (MFA)는 다운받는 방법을 알려준다.
파이썬 경험이 있다면 당연히 anaconda나 miniconda를 써본 적 있을 것이다. 만약 없다면, 이 기회에 컴퓨터에 아나콘다 🐍 한마리(?) 들여놓자. 인터넷에 검색하면 설치법이 나온다. 난 구글에 치니까 [이거] 나옴.
사실 이 글을 읽고 있으면 praat은 다들 갖고 있을 것 같다. 사실상 praat은 음성음운론자에게는 필수교양 같은 것이 아닐까? praat은 여기에서 다운받을 수 있다.
3.1.2 분석 파일: wav파일과 기본 textgrid
실습할 파일은 "수학처럼 딱딱"이다. 이것은 서울코퍼스의 S17F24F2파일의 일부를 추출한 것이다. 17번째 참가자로 24세 여성이다. wav 파일은 아래에 있다.
MFA는 아주 기초적인 수준의 음성전사를 요구하기 때문에 그것도 textgrid로 만들어서 아래 업로드했다. 명심하자 MFA는 Forced Aligner 이지 Forced Transcriber가 아니다.
이 파일들을 하나의 경로에 집어넣자. 나는 바탕화면에 'dirty'라고 폴더를 만들었다. 이 글에서 그 폴더를 [경로] 라고 호칭하겠다.
중요: 다운로드한 파일이름을 왠만하면 변경하지 말자. 만약 바꾸더라도 wav파일과 textgrid파일의 확장자를 제외한 파일명이 같아야한다.
3.2 MFA 설치
우선, Conda prompt에서 MFA를 구동할 conda environment를 만들어준다.
"-n" flag 뒤에 나오는 "mfa"는 마음대로 지정해도 된다. 이 부분은 앞으로 MFA가 설치된 파이썬 환경을 뭐라고 부르고 싶은지 사용자가 결정하는 부분이다. 나는 mfa라고 부르기로 했다.
conda create -n mfa python=3.10
끝났으면 conda activate mfa를 쳐서 해당 environment로 이동한다.
만약 맨 위에 conda create command에서 mfa 대신 다른 명칭을 사용했으면 (예: my_mfa), conda activate 에서도 그 명칭을 사용해준다. conda activate my_mfa 이렇게.
Conda prompt에서 아래와 같이 입력해서 MFA v.2.2.17 다운로드 받는다.
conda install -c conda-forge montreal-forced-aligner=2.2.17 openfst=1.8.2 kaldi=5.5.1068
한참동안 설치가 될텐데 컴퓨터가 일하게 좀 기다리자 (어디 컴퓨터가 일하는데 사람이 버릇없이 참견해! 😡)
잘 설치가 됐으면 MFA에게 첫 명령을 내려보자.
사람 처음 만나면 "니아버지모하시노" "몇살이세요?" 물어보듯 MFA에게 주는 첫 명령은 "몇살이세요?"다.
mfa version
MFA 버전은 2.2.15 이다. 미래에 읽고 있는 사람은 저것보다 버전이 높을 것이다. 그래도 부디 설명의 내용이 대동소이하기를 바란다.
3.3 Pre-trained Korean model 설치
그리고 우리는 한국어를 대상으로 할 것이기 때문에 아래의 command를 이용해서 한국어 음향모델과 발음사전을 다운로드 받자. 감사하게도 MFA 팀에서 음향모델을 사전훈련(pretrain)해주었다. [specifications] 물론 실제 연구에 사용하기 위해서 본인의 모델을 직접 훈련하는 것도 가능하다. 어쨌든 아래 커맨드 중 첫 줄은 한국어 음향모델을, 둘째 줄은 한국어 발음사전을 다운로드한다.
mfa model download acoustic korean_mfa
mfa model download dictionary korean_mfa
컴퓨터가 살짝 멍때리는 것처럼 보일텐데, 멍때리는 게 아니라 다운로드하는 중이니까 기다리자.
명령프롬프트가 아무런 대답도 안할텐데 모델이 잘 설치됐나는 어떻게 확인하나? inspect 명령어를 쓰면 된다.
mfa model inspect acoustic korean_mfa
mfa model inspect dictionary korean_mfa
각각의 명령에 대해 뭔가 긴 대답을 할텐데, 그것은 다운로드한 pre-trained model의 json형식의 신상명세라고 생각하면 된다. 잘 나왔으면 일단 패스하고, 더 궁금한 게 있으면 읽어보아도 재미있다.

3.4 Forced align하기
아래의 명령어를 사용하면 forced align해준다.
mfa align %USERPROFILE%\Desktop\dirty korean_mfa korean_mfa %USERPROFILE%\Desktop\dirty\output
거짓말 같지만 진짜 이 한줄의 command prompt 명령어가 끝이다.
MFA가 forced align한 결과는 [경로] 밑에 "output"이라는 새로운 폴더에 저장되어 있다. 들어가면 textgrid파일이 생성된 것을 확인할 수 있다.
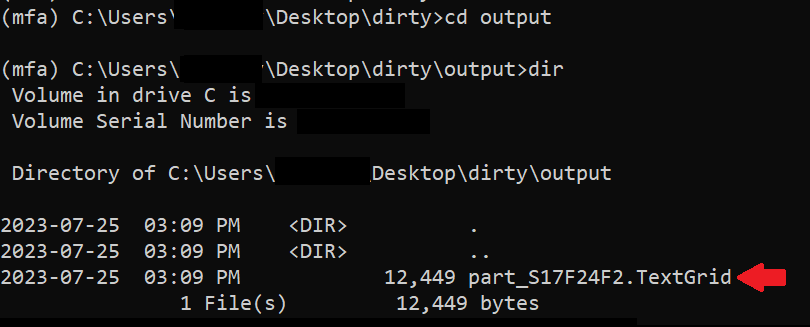
4. 제대로 됐나 확인하기
이제 MFA가 제대로 align했나 확인할 일만 남았다. 새로 생성된 textgrid 파일 ([경로] 아래에 있는 "output" 폴더에 있음) Praat에서 열어보자.
혹시라도 이 튜토리얼을 직접 하면서 따라오지 않은 사람들을 위해 결과 textgrid 파일도 업로드해놓는다.
제대로 됐나는 before and after 형식으로 보자.
[before]
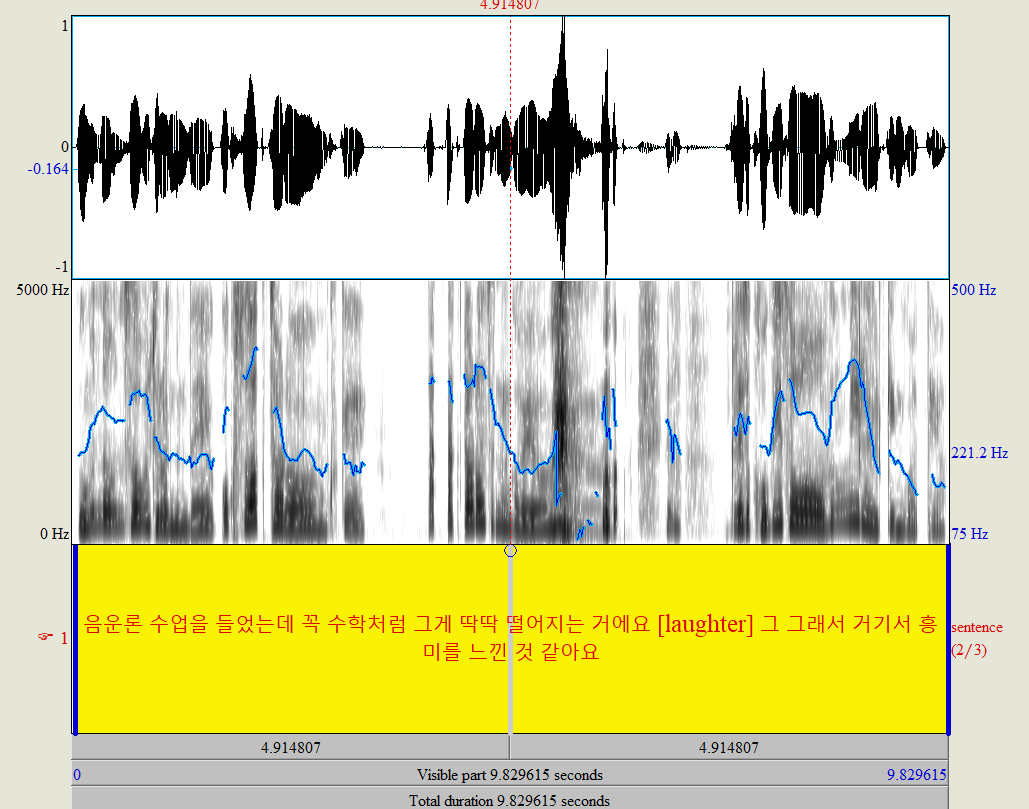
아이고 추해라.
MFA가 일한 결과는 아래에 있다.
[AFTER]
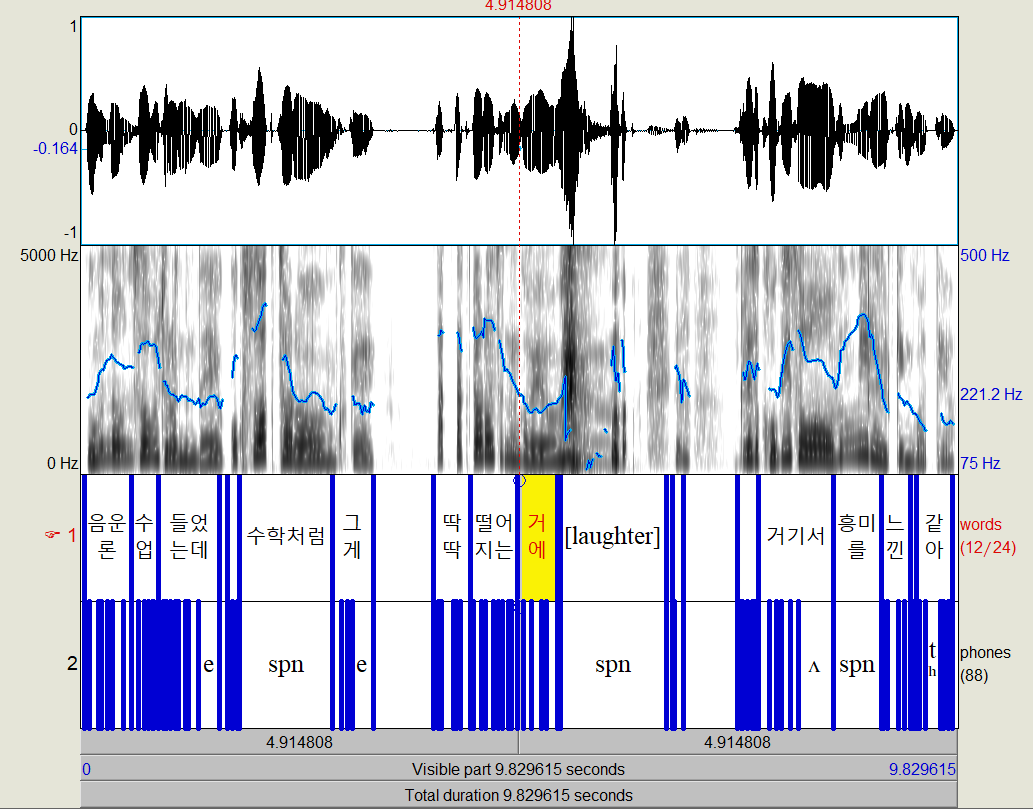
일단, 어절 수준으로 딱딱 나눠놨다. 이건 100퍼센트 사람이 한 것처럼 정확하게 나눠져있다.
그리고 phones tier를 보면 각각의 어절을 phone단위로 나눠놨는데, 가끔씩 spn이 보인다. spn은 "웃음" 등 당연히 말소리가 아닌 부분에도 있지만, "수학처럼" 이나 "흥미를"처럼 발음사전에 등재되어 있지 않은 단어들도 해당한다.
이런건 발음사전에 추가해주면 된다.
좀더 zoom in 해서 보자.
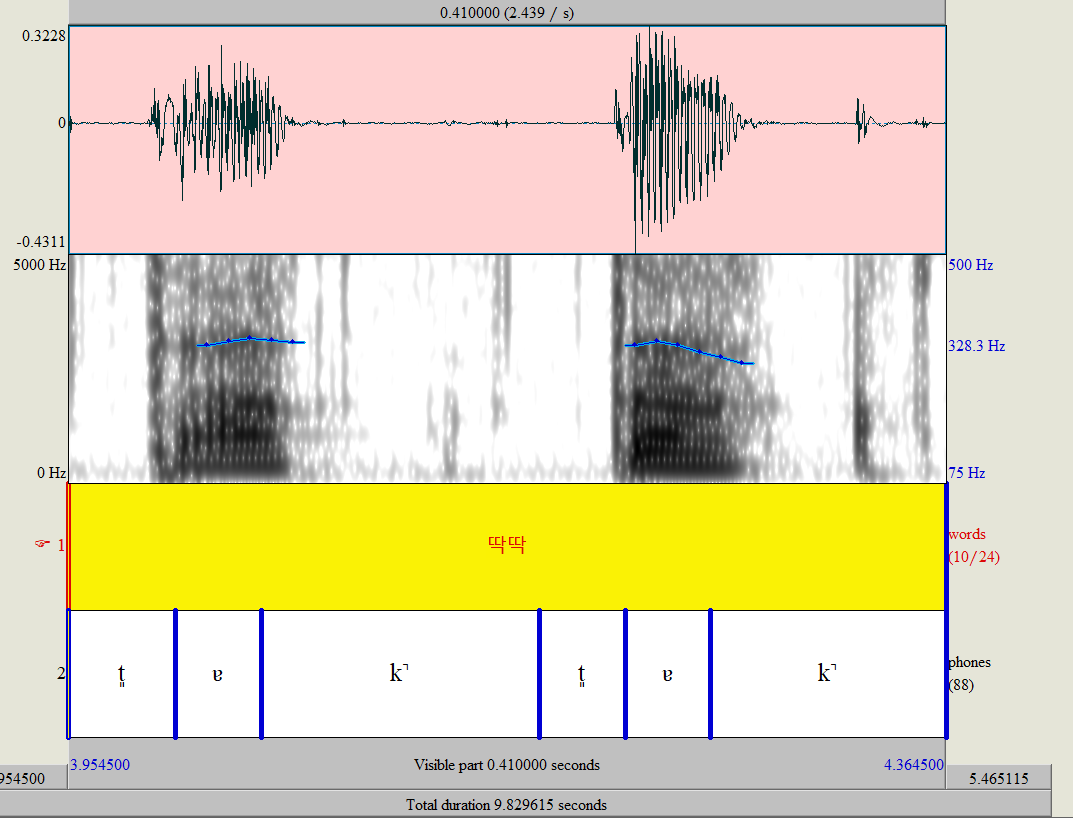
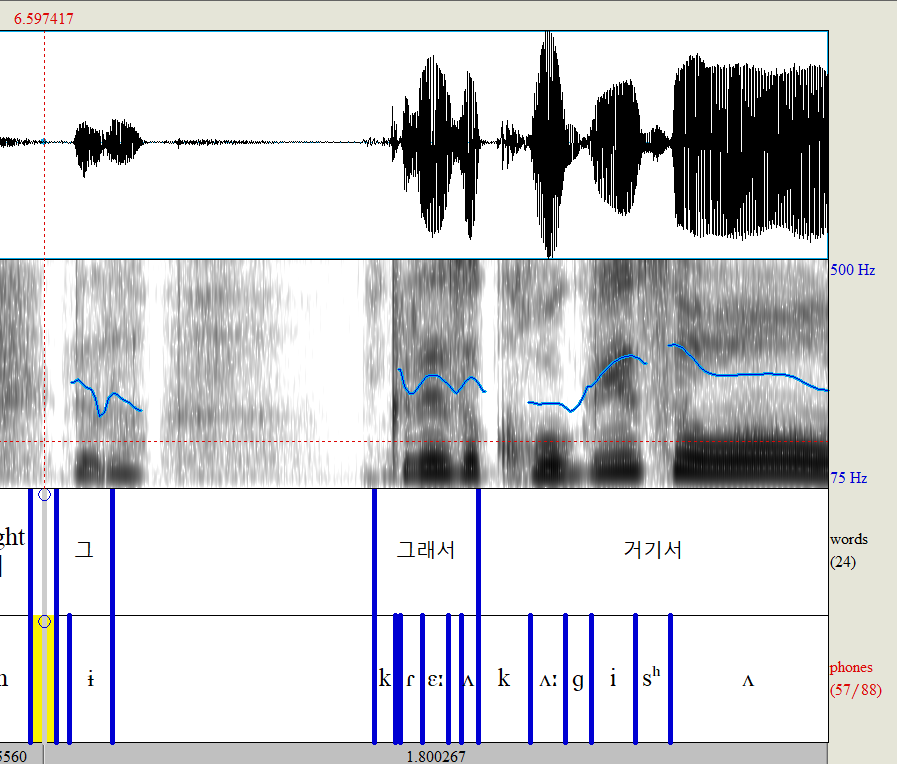
좋아할 것 같아서 다른 글도 준비했어요 |
- 아래에 댓글창이 열려있습니다. 로그인 없이도 댓글 다실 수 있습니다.
- 글과 관련된 것, 혹은 글을 읽고 궁금한 것이라면 무엇이든 댓글을 달아주세요.
- 반박이나 오류 수정을 특히 환영합니다.
- 로그인 없이 비밀글을 다시면, 거기에 답변이 달려도 보실 수 없습니다. 답변을 받기 원하시는 이메일 주소 등을 비밀글로 남겨주시면 이메일로 답변드리겠습니다.
'Bouncing ideas 생각 작업실 > exp sharing 경험.실험 나누기' 카테고리의 다른 글
| 음운론 전공자가 공부해본 통사론 (0) | 2023.09.01 |
|---|---|
| Mac에서 받은 파일 한글 깨짐 해결 (2) | 2023.08.20 |
| 지겨운 한국어 행간주석(interlinear gloss) 컴퓨터 시키기 (4) | 2023.04.24 |
| 대학원 오게 만드는 언어학 책들 (0) | 2023.04.16 |
| 실시간으로 한국어 최소대립쌍을 산출해보자 (2) | 2023.02.14 |