0. 요약
러시아어학 전공 과정생이신 누에고치 님의 블로그 "누에고치의 누리집"을 즐겨 보고 있습니다.
예전 글을 훑어보다가 아래 글을 발견했는데, 2023년 2학기에 쓰신 기말 레포트 토픽들을 소개해주신 글이었습니다. 제시하신 여러 연구주제들 중 당연하게도 "음성학(+음운론)" 쪽에 관심이 갔습니다.
2023-2학기 기말레포트 (등급성 반의어, 게임리뷰 감성분석, 음성학)
입학하자마자 얼레벌레 한 학기가 흘러가고 어느덧 학기가 끝나버렸다. 연구방법론(노어학개론) 요약: 영어 '등급성 반의어' 형용사에 대한 연구(Lee 2013)을 대상을 러시아어로 바꿔보기. (출현빈
nuee.tistory.com
요약: 소련 시절부터 현재까지 러시아 뉴스 아나운서 보이스를 추출해서 특정 음소에 대해 어떻게 발음하는지 시대별 변화를 praat로 분석. 즉, 과거 아나운서들의 '옛스러운' 발음이 음성학적으로 어떻게 나타나는가?를 보자는 것.
문제점: 우선 같은 음소를 일일히 찾아내기도 힘들고, 무엇보다 실험환경이 아니라서 엄밀한 통제가 불가해서 신뢰도가 낮음.
이것은 상당히 흥미로운 주제인 것 같습니다. 그리고 무엇보다 '문제점' 두 가지에 너무 통감했습니다.
첫번째 문제점(같은 음소 일일이 찾아내기 힘들다)은 Forced Aligner와 Phonological CorpusTools로 해결할 수 있을 듯해보여서 이 글에서 소개합니다.
혹시 이 분과 비슷하게, 날것의 음성 코퍼스만 많이 있어서 골치아프신 분들이 계시다면, 이 글을 통해 해결책을 찾을 수 있기를 바라면서 글을 씁니다.
목차

1. 데이터는 스스로 말하지 않는다
이 블로그에서, Montreal Forced Aligner를 한번 소개한 적이 있습니다. https://linguisting.tistory.com/107
자동으로 한국어 praat textgrid 생성 - Montreal Forced Aligner 사용법
0. 들어가기에 앞서 사용한 Montreal Forced Aligner 버전: 2.2.16 사용한 Korean Acoustic Model: korean_mfa (Version 2.0.0rc4.dev19+ged818cb.d20220404 사용한 Korean pronunciation dictionary: korean_mfa 음성녹음이 있다. Praat에서 음
linguisting.tistory.com
날것의 음성파일이라도, 원어민이 각 파일을 듣는다면 음운론적 결론(이사람 경음화했네, 이사람 모음을 길게 발화하네)을 곧바로 낼 수 있을 것입니다.
문제는 폴더 안에 음성파일 넣어놓는다고 얘네가 알아서 결론을 내주지는 않는다는 것입니다. 데이터는 그저 존재하기만 하고 스스로 의미있는 결과를 낼 수 없습니다. 그 아무리 인공지능이 발달했다 하더라도 음성파일을 한 폴더에 넣기만 하면 음성음운론 논문을 써준다는 모델은 듣도보도 못했습니다.🤔 결국 연구자가 연구 주제라는 렌즈를 데이터에 적용해서 분석이란 것을 해야 합니다.
음성파일이 1분짜리 한 30개 정도에 그친다면, 연구자가 직접 듣고 "내가 듣기에 이러하더라, 그리고 통계처리 여기" 이런식으로 분석할 수 있겠으나, 음성파일이 무진장 많을 때, 그리고 자연발화 등 연구 대상이 불특정하게 산재할 경우에는 그렇게 할 수 없습니다.
뭘 해야 할지 분명하다면 기계가 도움을 줄 수 있습니다. 특히 Forced aligner를 이용하면 음운분석을 위한 사전작업을 후딱 할 수 있습니다. 또한 Phonological CorpusTools를 통해 음운론에서 흔히 하는 양적분석을 쉽게 할 수 있습니다. 특히 PCT는 Forced aligner나 수작업으로 도출한 Praat TextGrid를 입력받아 처리할 수 있다는 것이 강점입니다.
Forced Aligner는, 이미 다른글에서 소개한 바 있으나, 날것의 음성파일로부터 음성음운론적 분석이 가능한 수준의 TextGrid Interval들을 도출해주는 데 도움을 줍니다. 아래의 그림을 보시면 감이 오시리라 생각합니다.
자동으로 한국어 praat textgrid 생성 - Montreal Forced Aligner 사용법
0. 들어가기에 앞서 사용한 Montreal Forced Aligner 버전: 2.2.16 사용한 Korean Acoustic Model: korean_mfa (Version 2.0.0rc4.dev19+ged818cb.d20220404 사용한 Korean pronunciation dictionary: korean_mfa 음성녹음이 있다. Praat에서 음
linguisting.tistory.com
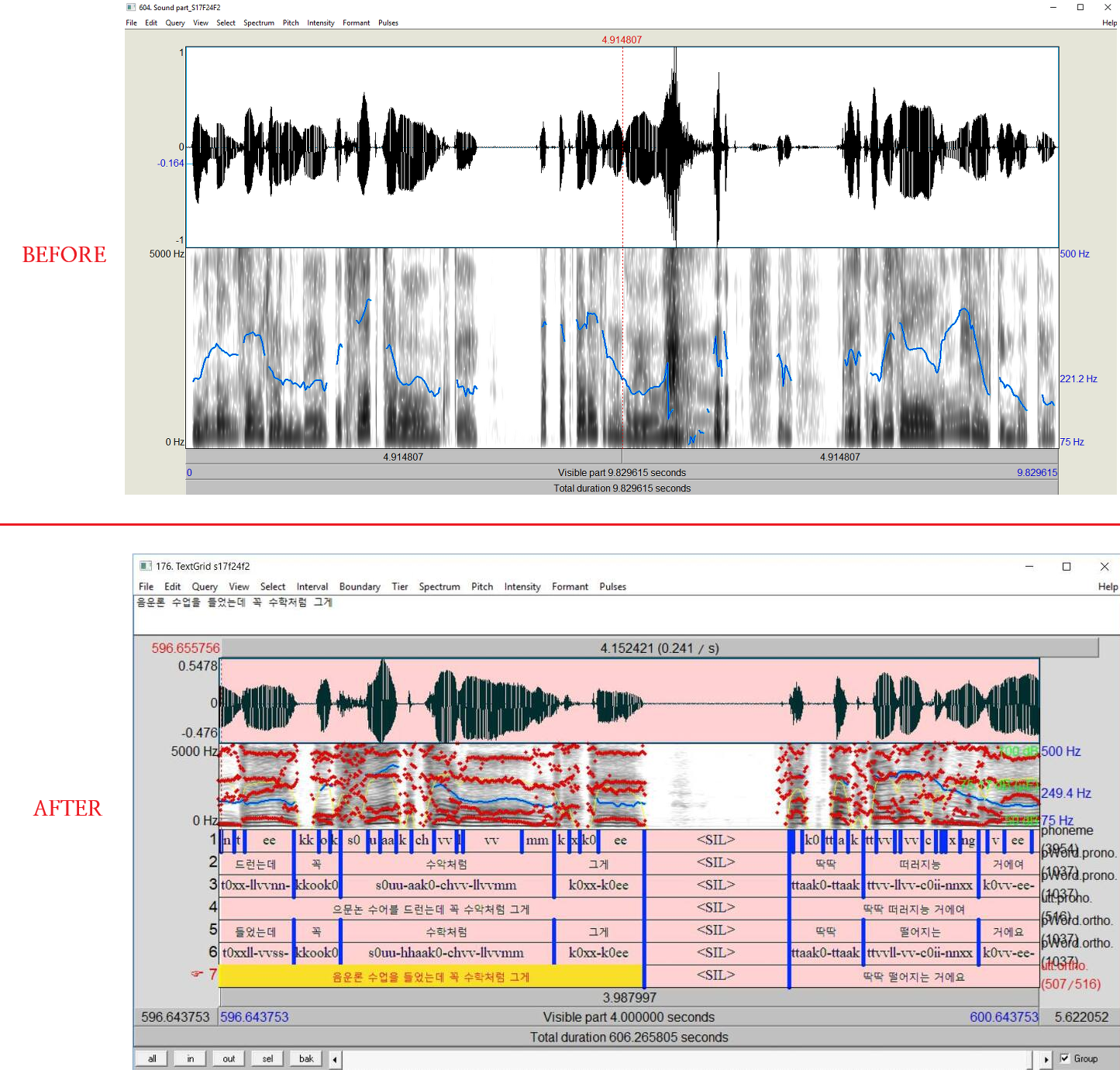
2. MFA 러시아어 모델
위에 언급한 제 블로그 글에서도 소개했지만, Montreal Forced Aligner는 음성파일을 자동으로 Praat TextGrid 형태로 전사해주는 툴입니다. MFA가 그 자체로도 훌륭한 툴인 이유는 사전훈련된 모델(pre-trained model)이 여럿 제공되기 때문입니다.
아래 웹페이지에서 사전훈련된 Acoustic 모델들이 소개됩니다.
https://mfa-models.readthedocs.io/en/latest/acoustic/index.html#acoustic
Acoustic models — mfa model 3.0.3 documentation
mfa-models.readthedocs.io
러시아어를 찾아보니 세 개가 있네요.
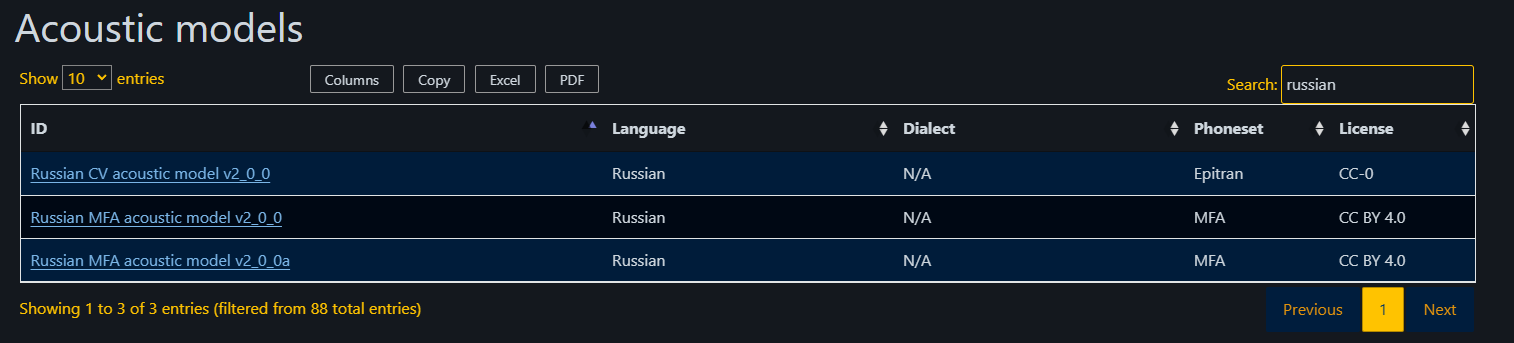
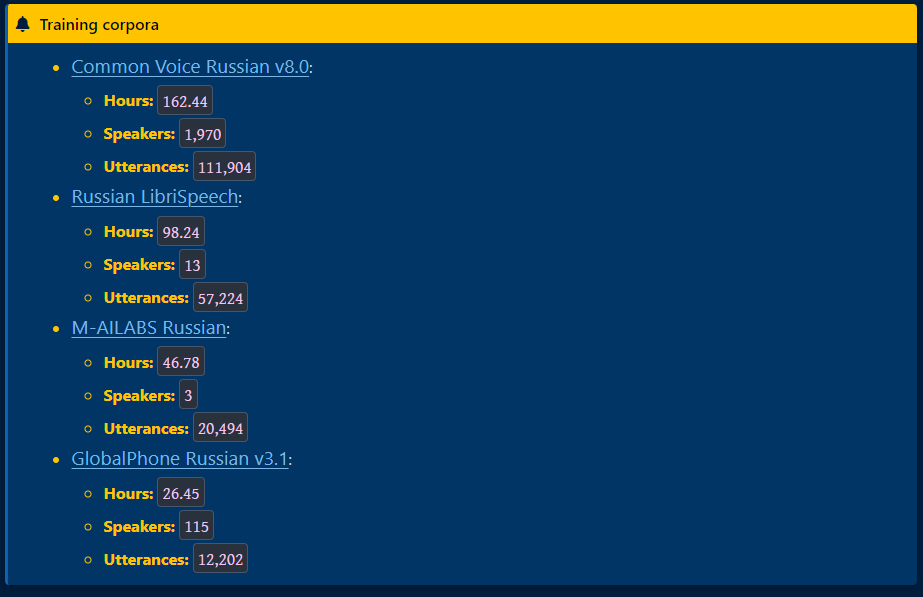
저는 두 번째로 리스팅 되어 있는 Russian MFA acoustic model v2.0.0 를 사용하겠습니다.
저는 러시아어전공자가 아니라서 훈련에 사용된 러시아어 음성 코퍼스의 품질을 평가할 자격은 안 되지만, 아래에 제시된 명세만 봐서는 적어도 양적으로는 훌륭한 자료들인 것 같습니다.
발음사전의 경우도 Russian MFA dictionary v2.0.0 가 있는데 그걸 쓰도록 하겠습니다.
Russian MFA dictionary v2.0.0 — mfa model 3.0.3 documentation
Maintainer: Montreal Forced Aligner Language: Russian Dialect: N/A Phone set: MFA Number of words: 416,098 Phones: a b bʲ bʲː bː c cː dzʲː dʐː dʲ dʲː d̪ d̪z̪ d̪z̪ː d̪ː e f fʲ fʲː fː i j jː k kː m mʲ mʲː mː n̪ n̪ː o p pʲ p
mfa-models.readthedocs.io
3. 실제 러시아어 데이터에 적용하기
MFA 모델을 한번 러시아어 뉴스 음성 데이터에 적용해볼까요?
3.1 원데이터
저는 러시아어는 인사밖에 할 줄 모릅니다. 고등학교 때 제2외국어가 러시아어였기 때문에 러시아어 문자는 읽을 줄 알지만, 진짜 다 까먹었습니다. 러시아어 음성 데이터는 당연히 없습니다.
그러나 인터넷 검색을 좀 해보니 독일 언론사 DW에서 러시아어 뉴스 서비스를 한다는 걸 알 수 있었습니다. 따라서 아래 영상에서 음성을 따와서 MFA에 돌려보겠습니다.
https://www.youtube.com/watch?v=yIWRS9dN9R0
The item included is used under the principles of "fair use" as outlined in Section 107 of the Copyright Act of 1976. It is provided solely for educational purposes to facilitate learning, research, and the advancement of knowledge. 여기 포함된 자료는 미국 1976년 저작권법 제107조에 명시된 "공정 이용" 원칙에 따라 사용됩니다. 학습, 연구 및 지식 증진을 촉진하기 위해 오직 교육 목적으로 제공됩니다.
구체적으로 위 뉴스 영상 중 13:54 부터 14:34 까지에 나오는 뉴스캐스터와 발화를 분석할 것입니다. 이 부분의 음성만 Sample rate 441000 Hz, sample size 16bit로 뽑아냈습니다. 따라하시기 편하도록 음성파일을 아래에 올립니다. 1
그리고 정서법으로 쓴 TextGrid도 있어야 합니다. 러시아어 정서법에 따른 스크립트가 있으면 좋지만, 저는 러시아어를 할 줄 모르므로, 유튜브에서 자동으로 음성인식한 결과를 가져왔습니다. 아래 파일로 첨부합니다.
3.2 MFA 돌리기
MFA가 설치되었다고 가정하고 terminal에서 MFA를 실행하겠습니다. 혹시 MFA가 아직 설치되어있지 않다면 아래 글을 참고해주세요
https://linguisting.tistory.com/107
자동으로 한국어 praat textgrid 생성 - Montreal Forced Aligner 사용법
0. 들어가기에 앞서 사용한 Montreal Forced Aligner 버전: 2.2.16 사용한 Korean Acoustic Model: korean_mfa (Version 2.0.0rc4.dev19+ged818cb.d20220404 사용한 Korean pronunciation dictionary: korean_mfa 음성녹음이 있다. Praat에서 음
linguisting.tistory.com
일단 버전을 확인하기 위해 terminal에서 mfa version 를 하면 2.2.17 임을 알 수 있습니다.

일단 위에서 언급한대로, 저는 러시아어 모델의 성능에 대해 판단 능력이 없으므로 사전 훈련된 것 중에 MFA 2.0 모델을 그냥 쓰도록 하겠습니다. 아래의 명령어를 사용했습니다. 만약 각 모델의 명세를 보고 어떤 모델이 좋다 하시면 그걸 골라서 다운로드 받으시면 됩니다.
mfa model download acoustic russian_mfa
mfa model download dictionary russian_mfa
사전 훈련된 러시아어 모델을 다운로드 받으셨으면, 러시아어 .wav file과 .textgrid file이 있는 폴더로 이동합니다. 그리고 나서 다음의 명령어를 사용하면 forced align 해줍니다.
mfa align ./ russian_mfa russian_mfa ./output
각 부분을 설명하자면 다음과 같습니다.
| 파라미터 | 값 | 의미 |
| mfa | mfa | mfa 야! |
| 수행할작업 | align | align 하거라. |
| 분석할 파일 경로 | ./ (현재 경로) | .wav파일이랑 .textgrid 파일 지금 경로에 있으니, |
| 발음사전 | russian_mfa | Russian MFA dictionary v2.0.0 이랑 |
| Acoustic model | russian_mfa | Russian MFA acoustic model 을 써서 |
| 출력 경로 | ./output | 지금 경로 밑에 output 디렉토리 만들어서 결과 출력해라 |
제 경우에는 한 1분정도 걸렸네요.

4. MFA 결과 평가
MFA를 돌린 결과 TextGrid 파일을 아래에 첨부합니다.
저는 러시아어에 대해 잘 모르지만, 소리를 들으면 그게 IPA 표기랑 얼추 맞는지 아닌지는 눈치껏 알 수 있습니다. 기계가 align해준 결과를 Praat으로 얼추 살펴보니 그럭저럭 괜춘하게 한 것 같습니다.
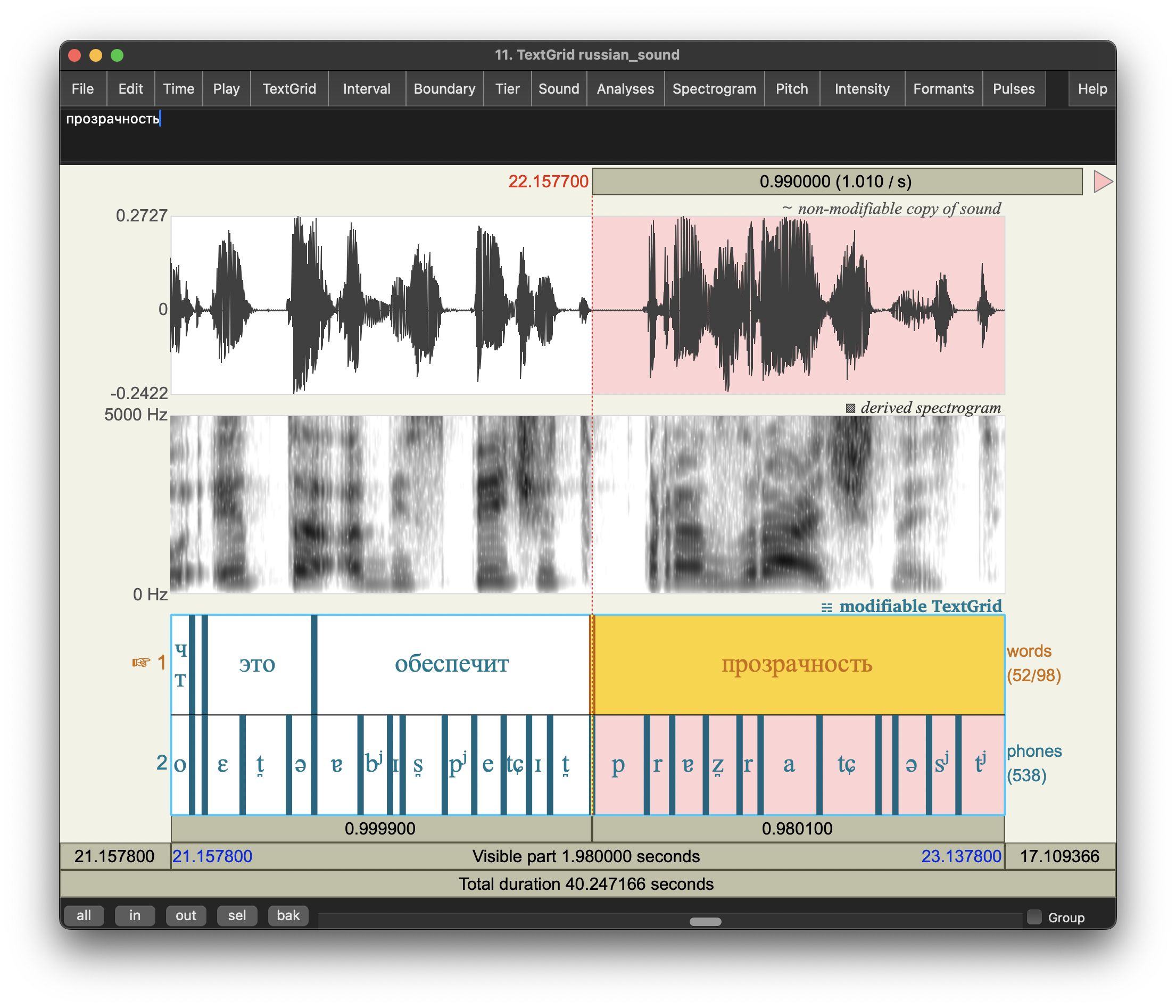
4. PCT에서 이어가기
이제, MFA를 통해 생성하거나 혹은 수작업을 통해서 많은 양의 TextGrid를 가지고 있다고 치고, 이걸 통해 음운론적 양적분석을 해봅시다. Phonological CorpusTools를 이용합니다. 물론, temporal analysis, spectral analysis 등 음성자질이 관심사라면 PCT가 별로 쓸모가 없지만, 기능부담, 음운이웃개수, 단어 내 변이 양상 등 음운론적 분석을 위해서는 PCT가 유용합니다.
우선 Phonological CorpusTools 1.5.1을 다운로드합니다. [다운로드 링크]
Releases · PhonologicalCorpusTools/CorpusTools
Phonological CorpusTools. Contribute to PhonologicalCorpusTools/CorpusTools development by creating an account on GitHub.
github.com
Documentation 에도 잘 설명되어 있으나, 다시 반복하자면...
File > Load corpus (단축키 Ctrl/Command + O) > Create corpus from file > TextGrid를 순서대로 따라가서 MFA로 생성한 textgrid를 불러옵니다.

MFA가 생성한 russian_sound.TextGrid를 그대로 불러오니 기본적인 파싱 예시를 끝낸 모습입니다. 그런데, 여기서 Phones Tier는 IPA 기호들이 있는 tier이기 때문에 'annotation type'을 Transcription (default)로 바꾸어줍니다.
PCT 코퍼스 파일 형태로 불러오면 아래와 같습니다. 고작 1분이 되지 않는 음성파일인데도 중복단어들이 몇개 보이네요.
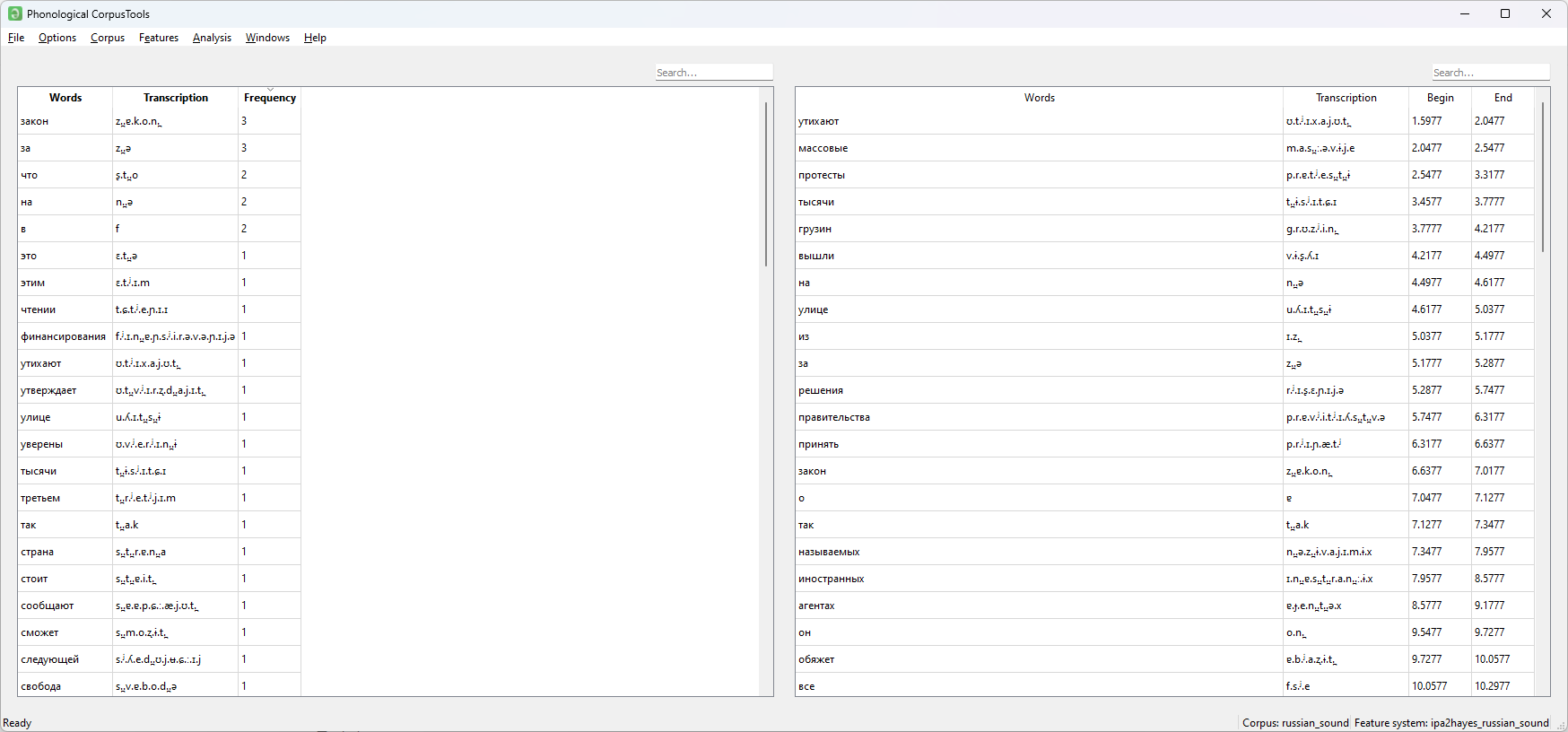
제가 러시아어학의 연구 관심사가 뭔지는 잘 모르고, 일단 코퍼스 사이즈도 너무 작기 때문에, 각 분절음의 출현빈도를 보도록 하겠습니다.
PCT는 documentation이 아주 잘 되어있는 프로그램이기 때문에 이 기능에 대해서도 설명이 잘 되어있습니다.
https://corpustools.readthedocs.io/en/latest/loading_corpora.html#summary-information-about-a-corpus
Loading in corpora — Phonological CorpusTools 1.5.1 documentation
Loading in corpora In order to use the analysis functions in PCT, you’ll first need to open up a corpus. When we say a “corpus” in PCT, we mean a file that has the following basic structure: a list of words with other possible information about each:
corpustools.readthedocs.io
러시아어 코퍼스를 불러온 채로, Corpus > Summary를 누릅니다. Corpus summary 창에서, 음소표에 각 음소를 누르면 type frequency와 token frequency가 자동으로 나옵니다.

- 글이 유익하셨다면 후원해주세요. Toss (국내결제) || BuyMeACoffee (해외결제카드필요)
- 아래에 댓글창이 열려있습니다. 로그인 없이도 댓글 다실 수 있습니다.
- 글과 관련된 것, 혹은 글을 읽고 궁금한 것이라면 무엇이든 댓글을 달아주세요.
- 반박이나 오류 수정을 특히 환영합니다.
- 로그인 없이 비밀글을 다시면, 거기에 답변이 달려도 보실 수 없습니다. 답변을 받기 원하시는 이메일 주소 등을 비밀글로 남겨주시면 이메일로 답변드리겠습니다.
- 유튜브 영상에서 제공되는 사운드 그대로 뽑아낸 것입니다. 단, 음성연구에 있어서 반드시 resolution이 높은 게 능사는 아닙니다.) [본문으로]
'Bouncing ideas 생각 작업실 > exp sharing 경험.실험 나누기' 카테고리의 다른 글
| Hangul to IPA 업데이트 중 (완료함) (3) | 2024.06.10 |
|---|---|
| ChatGPT는 Praat Script 짤줄 몰라 (0) | 2024.05.27 |
| 신경망 이용한 음운론 연구 workflow (feat. Fairseq) (0) | 2024.05.01 |
| fairseq translation task cross-attention 접근 쉽게하기 (0) | 2024.04.10 |
| Never assume anything (0) | 2024.04.02 |