0. 프리퀄
몰타어의 층위 구성에 대한 프로필은 여기
몰타어에 대한 역사적 개괄은 여기
1. Mifsud 1995
Mifsud 1995는 몰타어 외래어를 4가지로 분류한 박사논문이다. 한국어에서와 마찬가지로 몰타에서도 소위 '순혈주의' 언어관이 팽배한 것 같은데, 그런 측면에서 고유어화된 정도에 따라 외래어를 분류하는 것은 상당히 신선한 시도라고 (스스로) 자평한다.
어쨌든, 프리퀄에서 검토했듯, 몰타어에 들어온 유럽어 계열 외래어는 얼마나 오래전에 들어왔냐에 따라 형태론적 패턴이 다르다. 오래전에 들어온 외래어들은 아랍어와 유사한 패턴을 보이고, 최근에 들어온 외래어 (콜록 콜록) 영어 (콜록 콜록) 일수록 원어와 같이 접두사/접미사 붙이는 패턴을 따른다.
그런데 Mifsud 1995는 단순히 분류학적인 접근을 취하고 있기 때문에, 몰타어 연구자가 아닌 이론언어학자들의 입장에서는 요리재료에 해당한다. 그걸 가지고 요리를 하는 것은 이론음운론자들의 몫이다.
Mifsud는 몰타어 외래어의 유형을 4가지로 분류하였고, 감사하게도 그 중 첫 두 가지에 대해서는 단어목록을 제시해주었다. 나머지 3번유형과 4번유형에 대해서는 기준과 문법자질등을 소개했을 따름이다.
2. 차용어음운론적 접근
Frisch et al (2004)1에서는 형태론적인 측면이 아니라 음운론적인 측면에서 차용을 재조명했다. 이 논문에 의하면 시칠리아어 원어의 형태가 Maltese로 들어가면서 아랍어스럽도록 왜곡되었다고 한다.
아랍어 계통 언어들에는 OCP-Place 제약이 작용하는데, 그 강도는 언어에 따라 다르다. 몰타어도 아랍어 계통이므로 OCP-Place가 유효한 제약인데, 이 제약에 따라서, 외래어 중 동일 조음위치를 가지는 어휘들은 조음위치를 변경하는 등의 작용을 거친 후 차용되었다는 것이 요지다.
그런데 이 논문의 논증 과정이 조금 석연치않다. 이 논문의 근거는, '이탈리아어의 동일조음위치회피 정도'와 '몰타어 차용어들에서의 동일조음위치 회피 정도'를 비교한 결과치다. 이탈리아어(전체어휘)에서는 OCP-Place의 효과가 미미한데, 몰타어(차용어한정)에서는 OCP-Place 효과가 크다는 결과를 근거로, OCP-Place 제약의 실존을 주장한다.
이 논증에 있어서 숨겨진 전제는 두 가지다.
1. 이탈리아 어 렉시콘 전체가 몰타어로 차용되었다.
2. 몰타어 차용어는 이탈리아어 출신만 있다.
이 전제는 겉으로 드러내놓고 보면 받아들이기가 어렵다. 그러나, "몰타어에서는 차용어 층위에서도 OCP-Place가 유효하다" 라는 주장은 충분히 가능하다.
3. 나의 thesis
그런데 과연 몰타어에서도 음운론적 형태가 형태론적 선택에도 영향을 주는 것일까? 이것은 나의 질문이다. 나의 thesis는 어원정보는 학습이 불가능하기 때문에 음소배열적 정보를 통해 소위 어원을 유추한다는 것이다. 한국어에서 ㄹ-경음화는 한자어에만 한정적으로 유효한 규칙인데, 외래어 '장발장' [장발짱] 처럼, 외래어임에도 특정형태를 가진 것은 ㄹ경음화가 적용된다.
몰타어에서, 외래어임에도 아랍어처럼 non-concatenative morphology보이는 것과 유사하다.
만약 나의 주장이 참이어서, 역사적 층위 정보가 음소배열적으로 간접 학습될 수 있다면 몰타어에서도 음소배열에 따라 concatenative vs non-concatenative가 결정될 것이다.
Mifsud (1995)의 부록에는 차용정도에 따라 어휘군 A, B, C, D가 소개되어 있다. 그 중 어휘군 A와 B에 대해서는 속하는 어휘 전체를 제시하였다. 어휘군A는 어원론적으로는 외래어에 해당하나 사실상 고유어로 취급되는 어휘들이다. 한국어로 치면 "시소"나 "도대체", "포도" 같은 어휘다. 어휘군B는 A보다는 아랍어 형태론적 패턴을 덜 따라가는 어휘들이다.
나는 이 두 개의 어휘군이 OCP-Place의 측면에서 차이를 보이나 계산해보았다. 아래는 결과다.
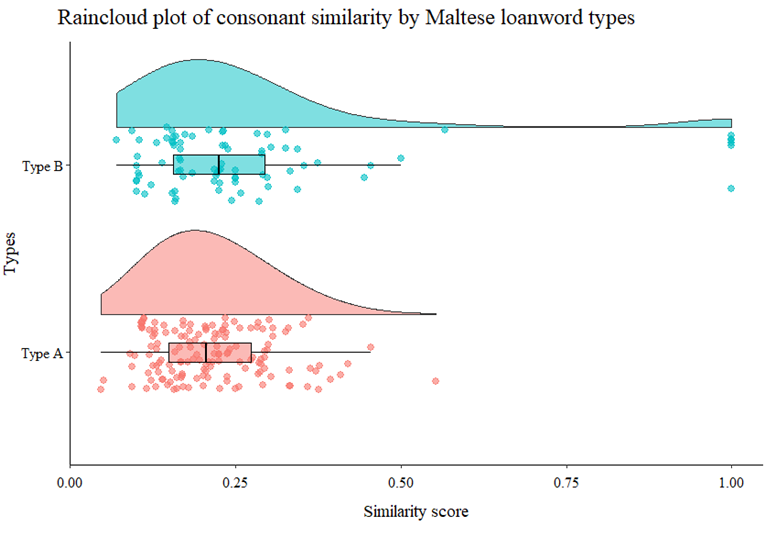
Similarity score가 낮을 수록 단어 내 자음들의 유사성이 낮다. Similarity score가 낮을수록 OCP-Place 의 효과가 크다고 할 수 있다. Type A의 similarity score가 살짝 더 낮아보이긴 하지만, 통계적으로 유의미한 결과는 아니다.
어쩌면 어휘군 A와 B는 우연한 (즉, 언어외적인 요인으로) 분리되어 있는 것일수도 있다. 실제로는 아예 고유어화(nativized)되어버린 어휘군 C와 D에서는 유의미한 결과가 나올 수도 있다.
4. Todo
그러므로 내가 할 일은 명확하다. Mifsud 1995가 제시한 어휘군 C와 D의 기준을 가지고 실제 코퍼스 자료를 분류하는 것이다. 즉, 몰타어 코퍼스에 나온 외래어 어휘들을 비둘기집 넣듯이 어휘군 A,B,C,D로 분류한다음 분류 간 음소배열적 차이가 있는지를 검증하면 될 일.
몰타어 코퍼스는 Ġabra 라는 db를 사용할 것이다. [링크]
- 아래에 댓글창이 열려있습니다. 로그인 없이도 댓글 다실 수 있습니다.
- 글과 관련된 것, 혹은 글을 읽고 궁금한 것이라면 무엇이든 댓글을 달아주세요.
- 반박이나 오류 수정을 특히 환영합니다.
- 로그인 없이 비밀글을 다시면, 거기에 답변이 달려도 보실 수 없습니다. 답변을 받기 원하시는 이메일 주소 등을 비밀글로 남겨주시면 이메일로 답변드리겠습니다.
- Frisch, S. A., Pierrehumbert, J. B., & Broe, M. B. (2004). Similarity avoidance and the OCP. Natural Language & Linguistic Theory, 22(1), 179-228. doi:10.1023/B:NALA.0000005557.78535.3c [본문으로]
'Bouncing ideas 생각 작업실 > lexical subclassing' 카테고리의 다른 글
| 어종 관여 작용의 생산성(productivity) 실험 정리하기 (0) | 2024.05.31 |
|---|---|
| 음운론 연구자가 Mac에서 fairseq 쓰려고 도전 (2) | 2023.12.11 |
| Maltese 역사 스케치 (0) | 2023.02.08 |
| Maltese profile (0) | 2022.07.11 |
| 인도 반도에서 쓰이는 언어들의 subclassing (0) | 2022.07.10 |