0. 맥락
- 나는 Bluesky 데이터로 연구하고 싶은 생각이 늘 있었고, 그래서 차용어음운론 논문을 쓰기로 함.
Twitter 대신 Bluesky 수집하기
0. 요약이 글에서는 Bluesky에 올라온 글을 수집하는 툴 blueskyscraper를 소개합니다. 목차 1. 왜 social media를 보아야 하나Social media (사회망: social network service)는 끝없이 쏟아져 나오는 언어표현의 원천
linguisting.tistory.com
- 주제는 도착어의 언어변화에 따른 차용양상 변화. https://linguisting.tistory.com/23
언어변화로 인해 차용양상에 변화가 생기는 경우
0. 요약다양한 언어가 서로 접촉하는 상황 속에서 주 언어(host language, L1)가 외국어(adapted language, L2)의 표현을 빌려오는 것은 흔한 일입니다. 한국어도 한자차용과 문명접촉의 맥락 속에서 고대
linguisting.tistory.com
- 구체적으론 서울한국어에서 ㅐㅔ가 융합(merger)되었는데 이 모음 융합이 영어차용에 어떤 영향을 줄까 궁금함.
- 역사적으로 (그리고 규범표기 상으로) 각 모음 기호가 영어의 특정 모음을 차용할 때 사용되어왔음. 즉 [æ] 모음은 ㅐ, [ɛ] 모음은 ㅔ로 차용됐음. 그런데 모음이 병합되었으니 이 매칭이 혼동될 것 아님? 실제로 배트민턴이 아닌 베트민턴, 밴쿠버가 아닌 벤쿠버, 패널티가 아닌 페널티가 흔함.
- 한국어의 변화에 따라 영어 차용양상도 따라 바뀐 건 사실 딱히 새로울 것도 없음. 한국어에서 단어첫 후두자질 (평음-경음) VOT F0 바뀌니까 이에 따라 영어의 유무성음 차용의 양상이 달라졌음. 옛날(1930년대)엔 유성음이 경음으로 차용되었는데 오늘날에는 평음으로 차용됨. (Kang 20081, Nam 20212).
- 근데, 실제로 ㅐㅔ가 혼동되고 그러더라도, 막 각잡고 쓰는 논문이나 신문기사 그런거에는 아닌 척 신경써서 ㅐㅔ를 구분해서 쓸 것 아님?
- 그래서 트위터(X)나 Bluesky처럼 힘빼고 아무말이나 하는 데이터를 써야 함. 근데 트위터는 일론 머스크가 먹은 후 데이터 접근 어려움.
- 어쨌든 '이런 연구 어때요?' 란 생각으로 낮은 수준의 conference인 ICKL에 abstract 제출하려고 생각중.[CfP link] (아예 미친 소리면 reject받을 것이고 그럼 주제를 접을 생각)

목차
1. Bluesky 수집
애초에 Moncomble (2025) BlueskyScraper를 쓸 생각이었으나, 오픈소스도 아니고 내 계정 정보를 그냥 입력하는 게 좀 꺼려져서 다른 방식으로 진행할 생각임. https://corpustools.prendrelangue.fr/blueskyscraper
BlueskyScraper
Cite this tool: Moncomble, Florent. 2025. ‘BlueskyScraper’. Web application. 2025. https://corpustools.prendrelangue.fr/blueskyscraper/. Download BibTeX file:
corpustools.prendrelangue.fr:443
찾아보니 python api 제공되므로 스크립트를 짜서 돌리는 게 좋을 듯하다.
https://atproto.blue/en/latest/index.html
일단 첫걸음으로 bluesky에 가입했음!
https://bsky.app/profile/sleepywug.bsky.social
sleepywug.bsky.social
bsky.app
그리고 노땅이라 그런지 브금은... https://youtu.be/FrTrZxy__GU
계획의 수정: 한국에서 bluesky를 사람들이 그렇게까지 많이 쓰지 않고 나 시간이 촉박하기 때문에 아래의 방식으로 진행한다.
- 1단계: Bluesky에 올라오는 포스팅들을 스트리밍으로 들으면서 한국어로 포스팅하는 사람들의 목록을 만든다
- 2단계: 각 사람들이 Bluesky에 올린 과거 포스팅들을 다 긁어온다.
1.1 1단계: 한국어 사용자 MoM
MoM은 여기 속어인데 대충 메일링리스트 정도의 의미. 미국 영어에서 roster 정도일텐데, roster가 야구에서 유래되었기 때문에 오늘날엔 널리널리 사용되는 것과 달리 MoM은 좀 출신성분(?)이 안 좋아서 아무래도 우리동네에서만 쓰는 듯하다.
한국시간 기준 2025년 11월 28일 새벽 05:45 부터 29일 새벽 5시까지 Bluesky에 올라온 모든 한국어 메시지를 수집했는데 40216개가 모였다. unique user count는 7183을 찍었다. 한마디로 한국어로 Bluesky를 하는 사용자 7183명을 알게 되었다는 뜻이다.
그런데 어떻게 이 사람들을 알게되었나 그래프로 그려보니, 사용자가 분명 더 있다!!

더 오래 돌렸으면 사용자 풀을 더 늘릴 수 있었을 것이란 점을 알게되었다. 내가 모든 사용자를 알게 되면 그래프는 푱푱해질 것이기 때문이다. 내가 만약 모든 한국어 Bluesky 사용자 주소를 가지고 있다고 했을 때, 아무리 새로 포스팅을 수집해도 그건 반드시 기존 사용자 중 하나로 pigeonhole될 것이기 때문.
각 사용자는 사용자명이 아니라 DID (decentralized ID) 로 인식되는데 DID는 'did:plc:ouyn24rwlsjbbxhlpvk7ixa3'와 같은 형식을 가지고 있다 (저건 내 개인 DID다). 한국어 사용자 DID 목록을 수집하면 2단계에서는 각 사용자에 대해 수집 가능한 모든 포스팅을 다 긁어올 것이다.
1단계에 사용한 코드는 여기에 남겨놓는다.
import json
from httpx_ws import connect_ws
BSKY_JETSTREAM = "wss://jetstream1.us-west.bsky.network/subscribe"
def export_userline(user, time, msg):
msg = msg.replace('\n', " ")
msg = msg.replace('\t', " ")
with open('userline.txt', 'a', encoding='utf-8') as f:
f.write(f"{user}\t{time}\t{msg}\n")
collected_lines = 0
with connect_ws(BSKY_JETSTREAM) as ws:
while True:
try:
received = ws.receive_text() # str
except Exception as e:
print(f"Encountered an error: {e}")
continue
msg = json.loads(received)# json structure
if msg['kind'] != 'commit':
continue
try:
commit = msg['commit']['record']
if msg['commit']['collection'] != 'app.bsky.feed.post':
continue
except KeyError as e:
continue
languages = commit.get('langs', []) # extract text language if exists
if 'ko' not in languages:
continue
export_userline(msg['did'],commit['createdAt'],commit['text'])
collected_lines += 1
print(f'# of collected rows: {collected_lines}')
실시간으로 올라오는 메시지를 보고있자니, 성인광고도 있지만 귀여운 것들도 있다.
> 할머니랑 아침먹고 둘이서 절인 배추 읏쇼읏쇼 다 씻음((헉.헉.힘들다. 술 진짜 안 마시는데 할머니가 맥주 한 잔 하재서 기분이다..!! 하고 마셨어용 종이컵으로 2잔 마셨는데 고대로 술기운 오르려고 함
https://bsky.app/profile/did:plc:anor4cq4y2yzd3yke7fplkx3/post/3m6nqpdsozk23
호지 _(•̀ω•́ 」∠)_ ₎₎… (@hozi-tea.bsky.social)
This post requires authentication to view.
bsky.app
1.2 2단계: 각 사용자별로 포스팅 모으기
일단 과거 포스팅을 다 수집하되 한 사람당 100,000개가 넘으면 편향된 데이터셋이 될 수 있으므로 최대 100,000개로 제한했다.
1.3 3단계: 전체 포스팅에서 외래어 사례 추려내기
2단계라며!
일단 abstract 빨리 완성해야 해서 preliminary로 208명의 사용자만 추려서 돌렸다. 분석한 총 포스팅의 개수는 535,082개이다.
그리고 아 맞다 박나영 (2020) 데이터셋 (이 홈페이지에서 2번째 데이터셋)을 기초로 대상 외래어 목록을 만들었다.
구체적으로 (i). 외래어 명사들, (ii). ㅐㅔ로 표기되는 사례들, (iii)ㅔㅣ 연쇄 없는 것들(ㅔㅣ연쇄는 /eɪ/의 차용임) 추려내니 4588개였다.
그런데 대상 외래어 중엔 '가네샤' 이런 게 포함되어 있었다. 에이 설마 이게 사용례가 있었어 했는데 두둥! 있었다! 2건이나 있었다! Bluesky는 도대체 어떤 플랫폼인걸까!ㅋㅋㅋ
생각보다 걸보스(...)들이 보임. 그리고 여주 남장시키는 클리셰는 조선에도 있었다 그로신: 너무 미쳐서 패러디는 한 바퀴 돌아 훈훈하게 만들 수 있음 이집신: 너무 점잖아서 현대인 눈에는 이상한 점이 더 눈에 띔 인도신: 위의 신화들보다 캐릭터성이 더 우주 저 멀리 가 있는데 (당장 가네샤 탄생 신화;), 컨텐츠 개발이 적은 이유는 현존하는 종교와 관련되어 있어서 딱 하나인듯 수메르신: 위의 신화들보다도 현대인과의 시차가 멂. 그야 최초 문명에서 나온 거니까... 근데 의외로 아 이거 씨발 이거다 싶은 부분이 있음.
이제 진지하게 이 이야기에서 이상한 점을 꼽으라면 '미라에 집착한 이유는 육신이 없어지면 영혼도 갈데 없다는 논리였는데 정작 명왕이라는 놈은 개같이 썰린 채 부활했음' 이라고 생각합니다 물론 나중에 이시스가 붙여주긴 했는데 파츠 좀 모자랐다며요.그리고 남은 파츠끼리 제대로 붙긴 했을까요? 아닐 거 같음 완벽하게 붙었으면 애초에 잘랐다는 신화가 필요없거든요 접합수술의 결과가 좀 더 눈에 확 띄는 가네샤 버전으로 생각해 봐도 코끼리 말고 자기 머리 도로 붙이는 플롯의 신화 따위, 만들 이유가 없죠 이상하게 전개되니까 전해지지
그냥 무식하게 nest for-loop로 돌리고 있다.
겉 for loop는 대상 외래어를 iterate하고:
....속 for loop는 수집한 535082개 포스트를 iterate하면서:
........대상외래어를 발견하면 카운트를 올린다!
이런 무식하고 느리겠지만 직관적인 구조. 느리다고 해봤자 M3 MacBook Pro에서 5분만에 다 돌아가긴 했다 (컴퓨터 성능으로 커버치는 무식함ㅋㅋㅋ)
"아 이거 그렇게 하는 거 아닌데" 라고 하더라도 할말없음. (어떻게 하는건지 알려주세요)

2. 수집결과와 논증
2.1 수집결과
Preliminary로 유저 208명 535,082개의 포스팅에서, ㅐㅔ가 포함된 외래어 4,588가 실제로 어떻게 사용되었나보았다.
deviation rate를 구했는데, 1-(correct/total) 이렇게 간단한 식이다. 아래는 50% 넘은 경우들 (즉, 소위 규범표기가 오히려 덜 선택된 경우. 예: damage를 '대미지' 대신 '데미지'라고 차용)
| 단어 | 총 출현빈도 | deviation rate |
| 대미지(damage) | 146 | 63.01% |
| 팩스(fax) | 40 | 60% |
| 내비게이션(navigation) | 12 | 58.33% |
| 애피타이저(appetizer) | 13 | 53.85% |
| 페널티(penalty) | 69 | 53.62% |
| 노스탤지어(nostalgia) | 8 | 50% |
흥미로운 지점은 '페널티' 빼고는 전부다 [æ]를 ㅔ로 표기한 것이라는 점이다. 한국어 화자가 '외래어'라는 층위에 ㅔ가 더 빈번하다는 '감'에 근거해서, 애매할땐 그냥 ㅔ를 써버리는 것일지 모른다.
2.2 베이스라인
언어변화(모음융합)의 결과로 뭔가뭔가가 일어났다고 말하고 싶으면 베이스라인이 필요하다. 당연히 규범표기가 하나의 베이스라인이 될 수 있겠고, 혹은 옛날 코퍼스가 있으면 그것과 비교할 수도 있을 것이다.
그리고 옛날 코퍼스 찾았다! 2015년 자료다. 트위터에서 외래어가 어떻게 사용되었나를 조사한 것이다.

(쉬운 비교를 위해 Bluesky로 얻은 표를 아래에 복사-붙여넣기하고 2015년 rate를 추가했다.)
| 단어 | 총 출현빈도 | deviation rate | baseline (2015) |
| 대미지(damage) | 146 | 63.01% | NA |
| 팩스(fax) | 40 | 60% | NA |
| 내비게이션(navigation) | 12 | 58.33% | 69.68% |
| 애피타이저(appetizer) | 13 | 53.85% | NA |
| 페널티(penalty) | 69 | 53.62% | 79.38% |
| 노스탤지어(nostalgia) | 8 | 50% | NA |
2015년 데이터가 놀랍게도 너무 빈약하다. 그 이유는, 김순임(2007)3의 소위 "상용 외래어" 중에서 ㅐㅔ가 들어간 형태 36개만 조사했기 때문이다.
3. 배경지식
3.1 Bluesky 이해하기 (내맘대로 정리)
난 Bluesky가 처음이다. 계정도 방금 만들었고. 그래서 ATProto documentation과 Bluesky documentation 그리고 다양한 Bluesky 애플리케이션 개발기를 찾아본 결과를 여기에 정리한다. 부정확하지만 그래도 감을 잡기 위해서 저해상도로 bluesky에 대해 개념화해보자.
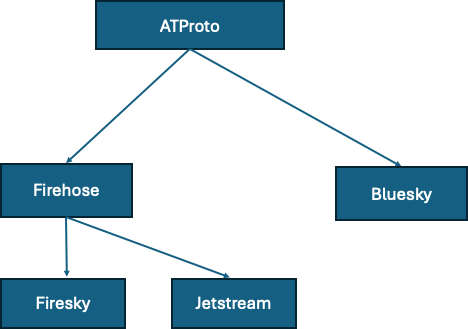
Bluesky는 약간 중개자?랑 비슷하다. 디스코드 서버처럼 포스팅 자체는 decentralized된 각각의 공간에서 이루어진다. 소모임 식의 비공개 서버일 수도 있고, 공개 서버일 수도 있고 등등. Bluesky 웹페이지 같은 곳에 들어가면 보이는 것들은 기계가 특정 PDS에 등재된 각각의 공간에 들어가서 포스팅들을 긁어오고 그걸 큐레이팅하는 것이다. 포스팅을 올리고, 포스팅을 긁어오는 기술이 ATProto. Bluesky는 거기에 옷을 입혀서 보기좋게 쨘.
그리고 ATProto를 활용해서 아싸리 지구상(?)에서 발생하는 모든 포스팅을 모아서 줄줄줄 토하게 만들 수도 있다. 🤮 이걸 firehose라고 하는 것같다. 이렇게 진짜 날것(raw) 상태를 그나마 보기좋게 (그러나 필터링 같은거 없이 모든 포스팅을 줄줄줄) json 형식으로 뱉어주는 게 Jetstream.
https://firesky.tv/ 같은 걸 보면 firehose를 직관적으로 경험(?)할 수 있다. 대혼란.ㅋㅋㅋ 인간들이 실시간으로 언어데이터를 생성해주는 과정!
정리:
사람들이 짧은 글을 올린다. 개인적으로 저장된다. 공개적으로 접근 가능할 수도 있고 아닐수도 있다.
ATProto: 이렇게 글을 올리고 글에 접근하는 protocol
Firehose: 접근가능한 글들을 줄줄줄
Jetstream: firehose를 json형식으로 예쁘게
Bluesky: ATProto 이용해서 짧은 글들을 각 사용자가 원하는대로 큐레이팅(예컨대, 팔로우하는 계정들만 보여준다거나, 특정 태그 글들만 보여준다거나, 검색기능을 제공하거나)
'인터넷 브라우징'은 매일매일 하는 거니까, 직관을 가지자면...
- http ~ ATProto
- Chrome ~ Bluesky
http 프로토콜이 있고 이 '약속'에 부합하여 정보를 올리고 내리면 서로 01110000 01101000 01101111 01101110 01101111 01101100 01101111 01100111 01111001 같은 걸 소통할 수 있다.
Chrome같은 브라우저는 웹서버에서 가져온 정보를 그림은 그림으로, 동영상은 동영상으로 글은 글로 큐레이팅해준다.
마찬가지로, 트위터에 올릴법한 짧은 메세지들을 ATProto에 따라 decentralized된 방법으로 올리고 내리고 한다.
Bluesky는 그걸 예쁘게 큐레이팅해주고 Firehose는 발생하는대로 줄줄줄 뱉어준다.
3.2 ㅐㅔ 융합
우선 merger를 우리말 용어로 '융합'이라고 부르는지부터가 애매. 전상범 교수님 <음운론>에서는 '통합'이라고 부르는데 논문에서는 융합이라는 용어가 보임. (아래에 소개된 박재익 2018 포함)
ㅐㅔmerger는 워낙에 한국어 음운론에서 유명한 토픽이므로 선행연구 묶음? 레파토리?가 있는데, 여기서 털어내고 가자면:
Eychenne and Jang 2015: 음성학실험논문 ㅐㅔ가 단순히 surface neutralized된 게 아니라 아예 하나의 음소가 되었다는 근거.
곽충구 1980: 통시논문인데 옛날옛적(막 조선시대) 기록에서 ㅐㅔ 철자 혼동 있었다는 내용
Hong 1987: 이건 흔히 'seminal paper'라고 부를 수 있을텐데, 특별히 새로운 주장때문에 인용한다기보다는, 영어권에서 이 토픽 얘기할 때 가장 시작점(?)으로 놓는 논문.
Lee&Cho 2021: 사회언어학 논문인데, 개인적으로 약간 끝판왕같은 느낌. 이 토픽 관련해서 가장 재밌게 읽은 논문이다. "왜 그리고 언제" 라는 질문에 뭔가 시원시원한 결론이 나왔고, 결론이 나오는 양상이 내 스타일이었음.ㅋㅋㅋ
아 그리고 박재익 (2018)에 따르면 동남방언에서 시작해서 확산되었다고 함. 사실 난 반대로 알고있었는데 (서울한국어에서만 융합이 완료되었고, 동남방언에서는 변별함) 내가 동남방언에 대해 뭘 알겠는가. 박재익 교수님 논문이면 그게 사실일 것이다.
3.3 Social media
Social media 데이터로 언어학하는 세미나도 있었는데, Jacob Eisenstein, Jack Grieve...등등 이쪽으로 파는 연구자들이 있다.
이것도 좀 정리할 수 있을 것같다. 다른 글에서 이미 좀 써놓은 듯함.
Twitter 대신 Bluesky 수집하기
0. 요약이 글에서는 Bluesky에 올라온 글을 수집하는 툴 blueskyscraper를 소개합니다. 목차 1. 왜 social media를 보아야 하나Social media (사회망: social network service)는 끝없이 쏟아져 나오는 언어표현의 원천
linguisting.tistory.com
https://linguisting.tistory.com/263
Twitter 대신 Bluesky 수집하기
0. 요약이 글에서는 Bluesky에 올라온 글을 수집하는 툴 blueskyscraper를 소개합니다. 목차 1. 왜 social media를 보아야 하나Social media (사회망: social network service)는 끝없이 쏟아져 나오는 언어표현의 원천
linguisting.tistory.com
- 글이 유익했다면 후원해주세요 (최소100원). 투네이션 || BuyMeACoffee (해외카드필요)
- 아래 댓글창이 열려있습니다. 로그인 없이도 댓글 다실 수 있습니다.
- 글과 관련된 것, 혹은 글을 읽고 궁금한 것이라면 무엇이든 댓글을 달아주세요.
- 반박이나 오류 수정을 특히 환영합니다.
- 로그인 없이 비밀글을 다시면, 거기에 답변이 달려도 보실 수 없습니다. 답변을 받기 원하시는 이메일 주소 등을 비밀글로 남겨주시면 이메일로 답변드리겠습니다.
- Kang, Yoonjung. (2008). Tensification of voiced stops in english loanwords in Korean. Harvard Studies in Korean Linguistics 12: 179-192. [본문으로]
- Nam, Sunghyun. (2021). The adaptation of English word-initial voiced stops in Korean: A diachronic approach. 음성음운형태론연구, 27(1), 3-25. [본문으로]
- 김순임. 2007. 외래어 인지도 이해도 사용도 및 태도 조사. 국립국어원. [본문으로]
'Bouncing ideas 생각 작업실 > exp sharing 경험.실험 나누기' 카테고리의 다른 글
| 줄이어폰 사례추가 (4) | 2025.10.15 |
|---|---|
| 2020년대 말뭉치에서 졸리다 의 품사 (2) | 2025.05.11 |
| 바보같은 실수 (0) | 2025.05.07 |
| Twitter 대신 Bluesky 수집하기 (0) | 2025.04.26 |
| Yale → 한글 (0) | 2024.12.24 |